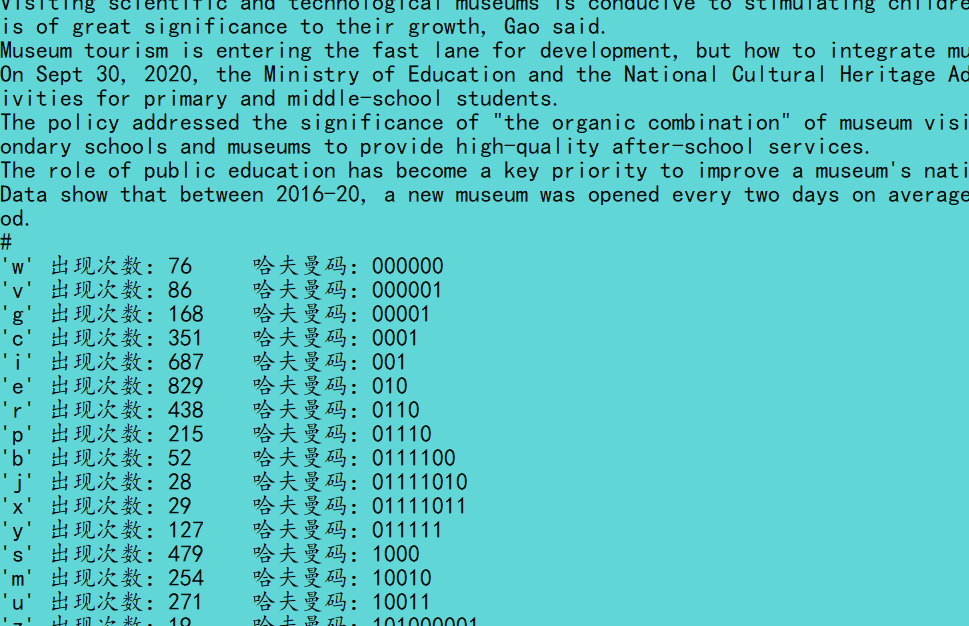
哈夫曼树的作用:哈夫曼树是为解决哪种问题发明的
哈夫曼树的构建原理:哈夫曼树详解
下面浅谈我个人对哈夫曼树的理解及其实现:
阅读网上的哈夫曼树构造方法后,可以发现这是一个重复的过程:提取森林中权值最小的两棵树,并将它们组成新树,再将这个新树再次放入森林,然后重复以上步骤。既然是重复步骤,那么就可以递归实现(实际上,递归也是最易懂,最优雅的方法)。图解如下:
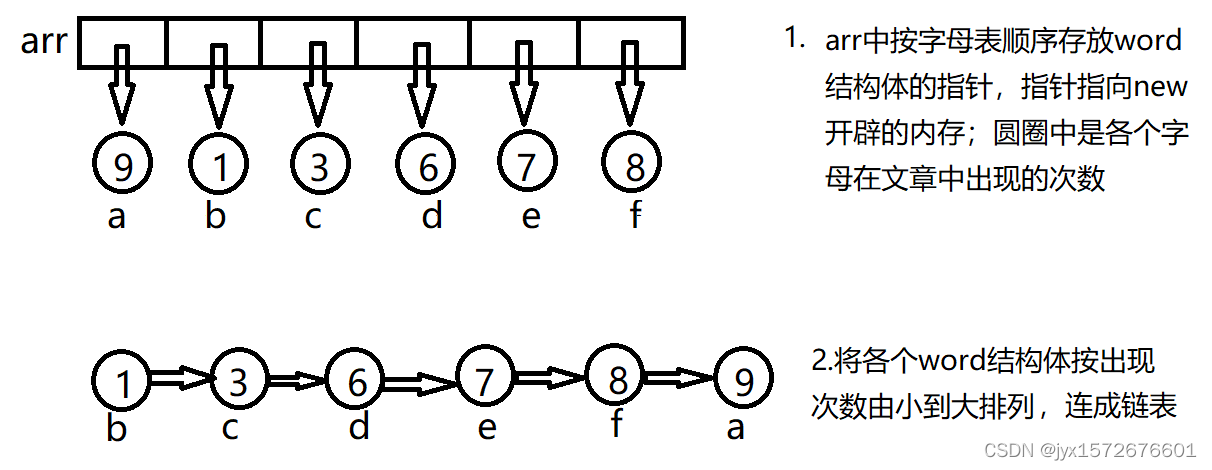
- 把链表第一个(b)和第二个节点©分别作为新根节点new_root的左右孩子,new_root的权值等于左右孩子权值之和,然后将new_root的权值和第三个(d)及其后面的节点权值依次比较,直到找到一个比new_root权值大的节点(找不到则放最后),并把new_root节点插入到此节点之前;重复上述步骤,图解如下:
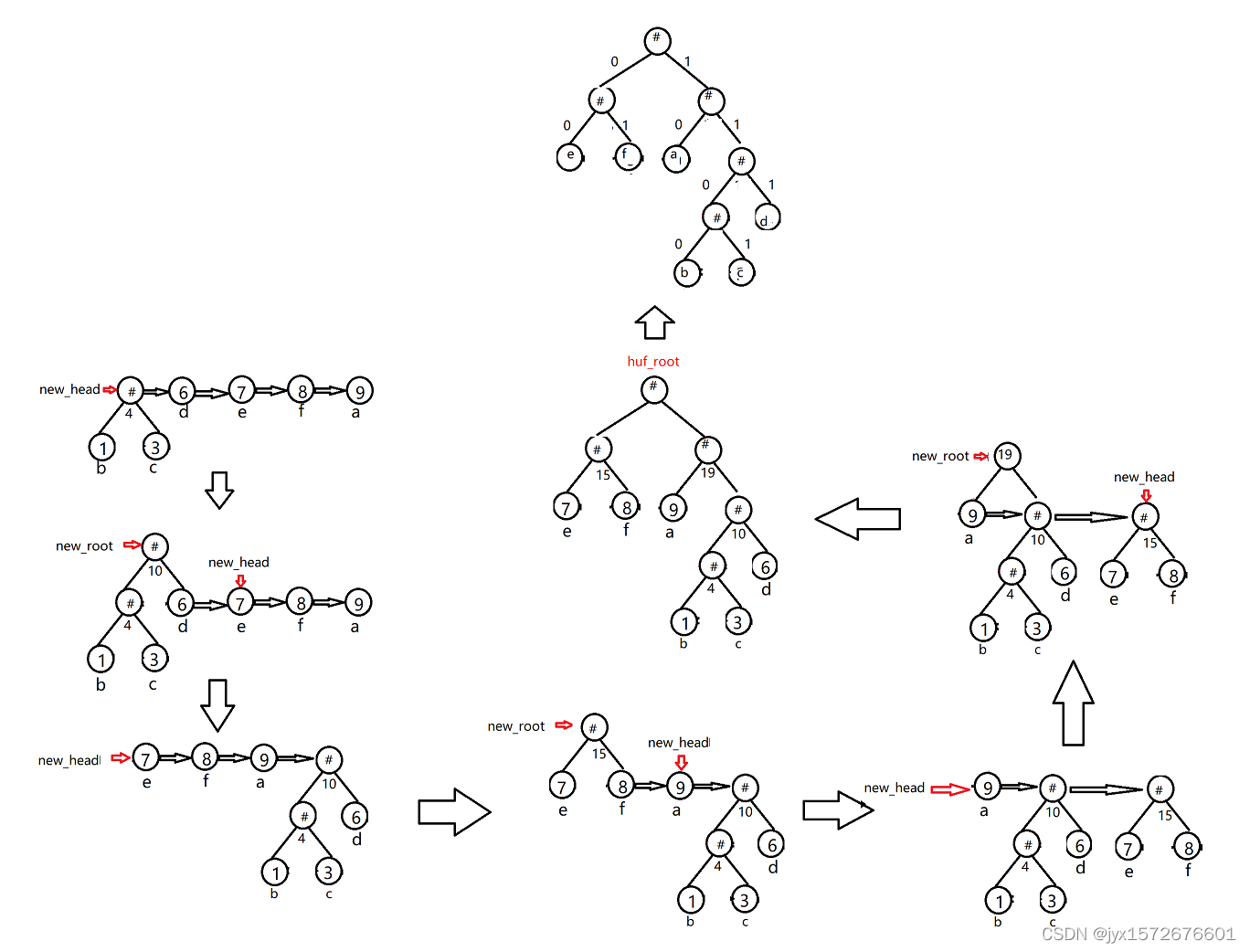
- 最后把左孩子的权值改为0,右孩子权值改为1,然后遍历树,对各个字母进行编码代码实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
| #include<iostream>
using namespace std;
struct huf_tree
{
char data;
int weight;
huf_tree* left;
huf_tree* right;
huf_tree* rlink;
string code;
};
struct words
{
char letters;
int counts;
};
huf_tree* cre_huf_tree(huf_tree*, int);
void ini_lett_arr(words**);
void essay_data(words**);
huf_tree* cre_link_list(words**);
void huf_coding(huf_tree* root,string);
void dis_code(huf_tree* root);
int main()
{
int n = 36;
words* letter_arr[36];
ini_lett_arr(letter_arr);
essay_data(letter_arr);
huf_tree* head = cre_link_list(letter_arr);
huf_tree* root = cre_huf_tree(head, n);
root->code = "";
huf_coding(root,"");
dis_code(root);
}
void ini_lett_arr(words** arr)
{
for (int i = 97; i <=122; i++)
{
arr[i-97] = new words;
arr[i - 97]->letters = i;
arr[i - 97]->counts = 0;
}
for (int i = 48; i <=57 ; i++)
{
arr[i - 22] = new words;
arr[i - 22]->letters = i;
arr[i - 22]->counts = 0;
}
}
huf_tree* cre_huf_tree(huf_tree* head, int n)
{
huf_tree* new_root = new huf_tree;
if (n == 2)
{
new_root->right = head->rlink;
new_root->left = head;
new_root->data = '#';
new_root->weight = new_root->right->weight + new_root->left->weight;
return new_root;
}
huf_tree* new_head = head->rlink->rlink;
huf_tree* temp = new_head;
new_root->right = head->rlink;
new_root->left = head;
new_root->data = '#';
new_root->weight = new_root->right->weight + new_root->left->weight;
head->rlink->rlink = NULL;
head->rlink = NULL;
int step = -1;
if (new_root->weight < new_head->weight)
{
new_root->rlink = new_head;
new_head = new_root;
}
else if (new_root->weight == new_head->weight)
{
new_root->rlink = new_head->rlink;
new_head->rlink = new_root;
}
else
{
while ((temp != NULL) && (new_root->weight > temp->weight))
{
step++;
temp = temp->rlink;
}
temp = new_head;
for (int i = 0; i < step; i++)
{
temp = temp->rlink;
}
new_root->rlink = temp->rlink;
temp->rlink = new_root;
}
return cre_huf_tree(new_head, n - 1);
}
void essay_data(words** arr)
{
cout << "输入文段(以'#'结尾):" << endl;
char letter = getchar();
while (1)
{
if ( letter >= 97 && letter <= 122)
{
arr[letter - 97]->counts++;
}
if (letter >= 48 && letter <= 57)
{
arr[letter - 22]->counts++;
}
if (letter >= 65 && letter <= 90)
{
arr[letter + 32 - 97]->counts++;
}
letter = getchar();
if (letter == '#')
break;
}
}
huf_tree* cre_link_list(words** arr)
{
for (int i = 0; i < 35; i++)
{
for (int k = 0; k < 35 - i; k++)
{
if (arr[k]->counts > arr[k + 1]->counts)
{
swap(arr[k], arr[k + 1]);
}
}
}
huf_tree* head = new huf_tree;
head->weight = arr[0]->counts;
head->data = arr[0]->letters;
head->right = head->left = NULL;
huf_tree* temp_head = head;
for (int i = 1; i < 36; i++)
{
huf_tree* huf_node = new huf_tree;
huf_node->weight = arr[i]->counts;
huf_node->data = arr[i]->letters;
huf_node->left = huf_node->right = huf_node->rlink = NULL;
temp_head->rlink = huf_node;
temp_head = temp_head->rlink;
}
return head;
}
void huf_coding(huf_tree* root,string code)
{
if (root->right==NULL || root->left==NULL)
{
return;
}
root->left->code = code + "0";
huf_coding(root->left,root->left->code);
root->right->code = code + "1";
huf_coding(root->right,root->right->code);
}
void dis_code(huf_tree* root)
{
if (root == NULL)
return;
if (root->data >= 97 && root->data <= 122&&root->weight!=0)
{
printf("'%c' 出现次数:%-4d 哈夫曼码:", root->data, root->weight);
cout << root->code << endl;
}
dis_code(root->left);
dis_code(root->right);
}
|