路由器中的排队与调度
经过上一篇文章《路由器的工作原理》的学习,我们应该发现当端口的处理速率与交换结构的转发速率不匹配时,就可能发生排队(Queuing);以何种方式调离队列中的分组,称之为调度(Scheduling)。本文将详细讨论这两个问题。
何处出现排队
排队的位置和程度取决于流量负载、端口处理速率以及交换结构的转发速率,当端口处理速率和转发速率不匹配时,就会发生排队。当队列占满整个缓冲区时,路由器将无法接收到新的分组,这时就会产生 丢包(packet loss) 。在 TCP 一章的讨论中,我们经常说到的丢包就在这里产生。
输入排队
如果交换结构的转发速率慢于输入端口的处理速率,就会在输入端口发生排队,因为到达的分组必须加入输入端口队列中,以等待通过交换结构传输到输出端口。在输入端口的排队大致能分为两种类型:1.端口竞争;2.队头阻塞(Head-Of-The-Line, HOL) 。如下图所示:
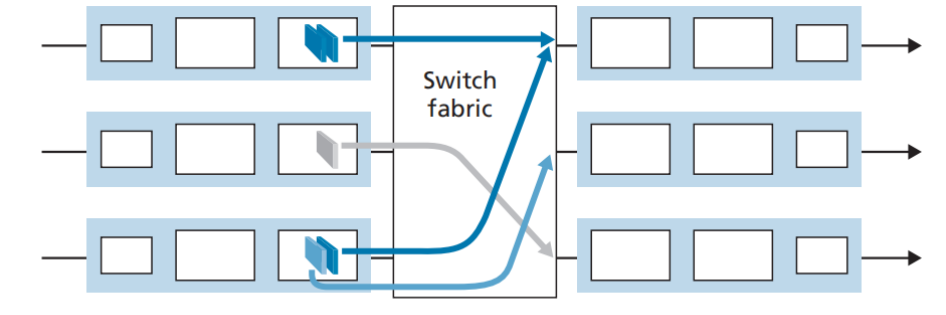
端口竞争
如图,当第一排端口的队头分组和第三排的队头分组要发往同一个输出端口时,就会发生排队。即使不发往同一个端口,由于交换结构种类的限制,也可能发生排队,比如经总线交换和经内存交换每次只能交换一个分组,而 crossbar 交换也并非任何时候都能实现并行交换,详见《路由器的工作原理》。
HOL
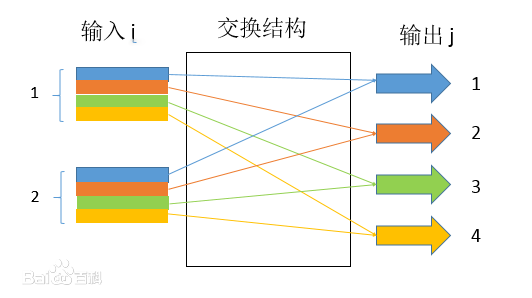
如上图,当发生端口竞争时,第一排队头先交换,第三排队头等待;由于第三排队头的阻塞,即使第三排队尾的分组的目的端口为第二排输出端口(没有端口竞争),其也无法发送(FIFO策略),这种阻塞就叫做队头阻塞。有研究表明,由于 HOL 阻塞,只要输入链路上的分组到达速率达到队列容量的 58%,输入队列的长度就将无限增大,导致大量丢包,所以 HOL 是输入队列面临的首要问题之一。解决 HOL 的主流方法是使用 虚拟输出队列(Virtual Output Queues) 。虚拟输出队列总体的想法十分朴素:在输入端口将发送到不同端口的数据包虚拟成不同的队列,并且彼此互不影响,这样一来即使队头数据包被阻塞也将不会影响发送到其他端口的数据包的发送。如下图 2 × 4 的输入输出交换结构中,每个输入端口将根据数据包输出端口的不同而加入专属“虚拟队列”(图中以不同的颜色区分),这样一来,在同一输入端口而目的端口不同的数据包的发送将彼此互不影响。除了虚拟输出队列外,还有其他许多解决排头阻塞的算法,如神经网络、iSLIP等等。
只有在缓存式输入的交换机中才会出现队头阻塞的情况,如果交换机内部的带宽足够的话,缓存输入就是没有必要的了——所有的缓存都可以在输出处被处理,从而也避免了队头阻塞。这样的无缓存式输入架构在中小型规模的乙太网交换机中非常常见。
输出排队
当交换速度较慢时,可能在输入端口形成排队;那么当交换速度足够快时,就能避免队列的形成吗?答案是否定的。即使 ,一旦当大量分组需要从不同输入端口传输到同一个输出端口时,队列也会在这个输出端口形成。当没有足够的内存来缓存分组时,要么将其丢弃(drop-tail),要么删除队列中的某个分组来为新分组腾出空间。有时可能会在队列被填满之前就主动丢弃新分组,以此向发送方提供拥塞信号,这种策略被称为 主动队列管理(AQM) 算法。
多少缓存才足够?
通过上述的简单讨论,不难发现似乎都是因为队列空间(缓存)不够大才造成的丢包,那么我们直接扩大路由器的缓存不就行了吗?事实上,确定合适的缓冲大小是一个复杂的问题。缓存设置过小会发生丢包,这不难理解;缓存设置过大,即使不会丢包,但也会引发高延迟并形成恶性循坏,其危害甚至比丢包更为严重 !这就是臭名昭著的 缓冲膨胀(buffer bloat) 。大多数TCP拥塞控制算法都依靠测量丢包的发生来确定连接两端之间的可用带宽 。该算法会加快数据传输速度,直到数据包开始丢失,然后降低传输速率。理想情况下,他们会不断调整传输速率,直到达到链路的平衡速度为止。为了使算法能够选择合适的传输速度,必须及时收到有关丢包的反馈。使用大容量缓冲区时,数据包虽然最后会到达目的地,但延迟较高。因为数据包没有丢失,所以即使上行链路饱和,TCP 也不会减慢速度,从而进一步导致缓冲区饱和,从而进一步造成高延迟,这对实时类应用无疑是致命的。
缓冲膨胀的解决可以从两个角度切入:针对网络的解决方案和针对端点的解决方案。前者通常采用队列管理算法的形式,如 AQM 算法;后者包含 TCP 的 BBR 算法,详见笔者另一篇文章《TCP拥塞控制详解(二)》。关于缓存大小的经验法则是: ,其中 C 是链路的容量,RTT 是平均往返时延。
分组调度
队列形成后,我们自然会考虑如何将分组调离队列并发送。就实际生活而言,一般我们排队会遵循 先到先服务(FCFS, 也称之为先进先出(FIFO)) 策略;然而我们也经常在车站售票窗口看见“军人优先服务”。类似地,路由器中的队列也有不同的排队策略,这些方式叫做 分组调度(Packets Scheduling) 。
先进先出(FIFO)
先进先出属于典型的被动队列管理的方法,它调度包的方法是:先到达路由器的分组先被传输,其它分组采用默认的排队方式。然而,路由器的缓存总是有限的,如果分组到达时缓存已满,那么路由器就不得不丢弃该分组。由于 FIFO 总是丢弃队尾的分组,所以又称它为“去尾”(drop-tail)算法。FIFO和“去尾”是最简单的分组调度和丢弃策略,两者有时可被视为一体,简单称为 FIFO 排队。
FIFO排队的算法简单,实施容易,是目前Internet使用最为广泛的一种方式。然而 FIFO 无法“识别”面向连接的连续 TCP 数据流,当存在占用大量带宽的对 TCP 不友好的流时,网络可能会持续拥塞,TCP 流分享不到应有的带宽。
优先权排队(priority queuing)
在此规则下,到达的分组根据既定规则被划入一个优先权类,每一个优先权类都有自己的队列,同一个队列中的分组采用 FIFO 策略 。如下图,分组 1、3、4 属于高优先权类,分组 2、5 属于低优先权类。分组 1 达到后即开始传输,在这期间分组 2、3 相继到达;分组 3 的优先权高于分组 2,所以分组 1 传输完成后轮到 3 传输;分组 4 在分组 2 传输时到达,在 非抢占式优先权排队 规则下,一旦分组开始传输,就不能被打断,所以即使分组 4 的优先权高于分组 2,也需要等到分组 2 传输完毕后才能传输分组 4 。
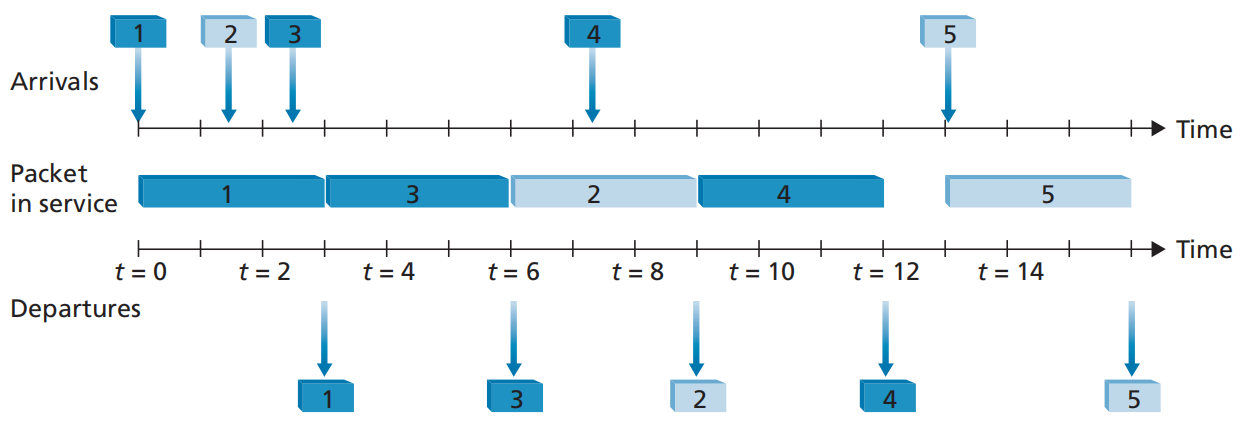
然而,虽然高优先级业务的带宽和时延得到了最大限度的保证,但若高优先级业务持续占据带宽,会导致低优先级业务一直得不到调度,这显然是不公平的,所以有了下面的 轮循和加权公平排队 策略。
轮循和加权公平排队(WFQ)
WFQ是在发生拥塞时稳定网络运行的一种自动的方法,它能提高处理性能并减少分组的重发。WFQ主要有三个目的:
-
为每个活动流提供公平的带宽分配机制,即WFQ名字中的F(fairness)的含义
-
为少量交互流提供更快的调度机制
-
为高优先级的流提供更多的带宽
WFQ 根据流对报文进行动态分类,分类判据可为五元组和 IP 服务类型(TOS字段),然后使用 Hash 算法映射到不同的队列中。另外,如果使用WFQ,那么 low-volume(字节数小的报文)、higher-precedence(优先级高的报文)的流会比 large-volume、lower-precedence 的流更先处理(目的二)。在出队的时候,WFQ 按流的优先级来分配每个流应占有出口的带宽。优先级的数值越小,所得的带宽越少。优先级的数值越大,所得的带宽越多。这样就保证了相同优先级业务之间的公平,体现了不同优先级业务之间的权值。详细内容参考[WFQ](WFQ_百度百科 (baidu.com)) 。





