路由器的工作原理
本文主要讨论网络层数据平面中的转发功能的硬件实现,即如何将分组从路由器的输入链路传输到合适的输出链路。
下图展示了通用路由器的一般结构:
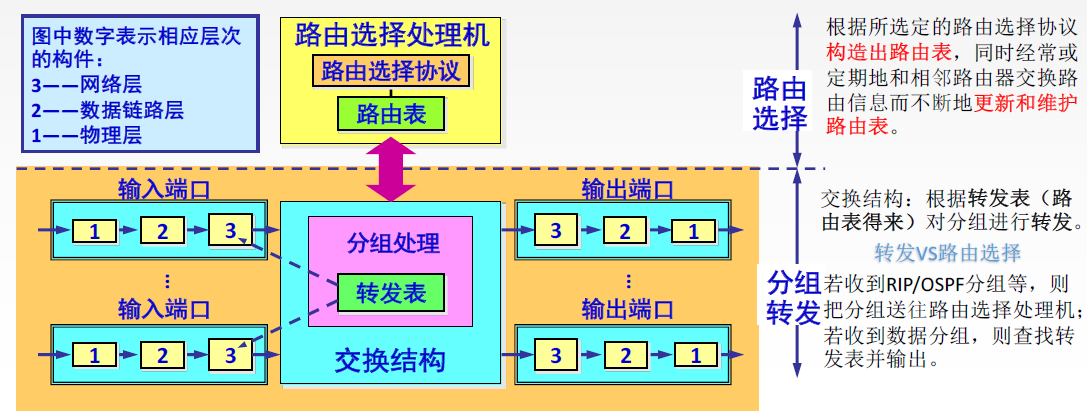
我们可以从图中看到,路由器大致有 输入端口、输出端口、交换结构、路由处理器 四个主要组件,下面我们简单分析各个组件的功能:
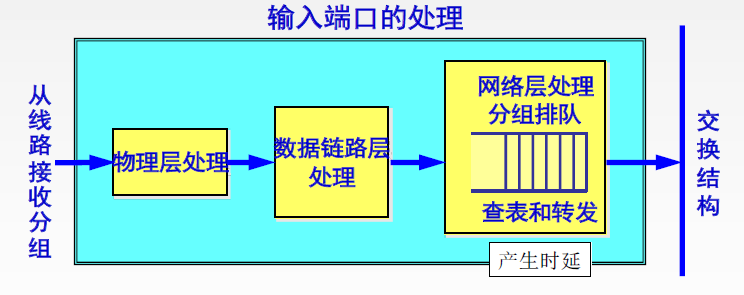
输入端口
1 号部分负责物理层功能:PHY(Physical Layer Device)模块或者 MAU(Medium Attachment Unit)模块将信号转换成通用格式,并将信号发送给 MAC 模块;
2 号部分负责链路层功能:MAC 模块收到 PHY 模块发来的信号后,将信号转换为数字信息,到达信号末尾时检查 FCS,如果 FCS 出错则直接丢弃此分组 ,若无错则 再检查分组 MAC 头部中的接收方 MAC 地址是否与自己一致 ,若不一致则直接丢弃,若一致则去掉 MAC 报头并将数据部分移交给网络层;
3 号部分负责网络层功能:查询转发表 ,决定此分组的输出端口;
为了更清楚地了解 PHY 和 MAC 模块在输入与输出端口中的作用,我们来看看电脑的网卡是如何将信息发送到网络中的:
首先,MAC 模块从报头开始将数字信息按每个比特转换为电信号(通用信号),这里注意,将数字信号转换为电信号的时间就是我们所说的传输时延 ;然后 PHY(MAU) 模块将电信号转为转换为可在网线上传输的格式,并通过网线发送出去。不同链路有着不同的信号格式,但 MAC 模块不关心这些区别,它只负责将数字信号转换为通用信号并转发给 PHY 模块,然后 PHY(MAU) 再将其转换为可在网线上传输的格式 。接收网络中的信号是上述过程的逆过程,不再过多阐述。
下面我们详细了解路由表的查询:
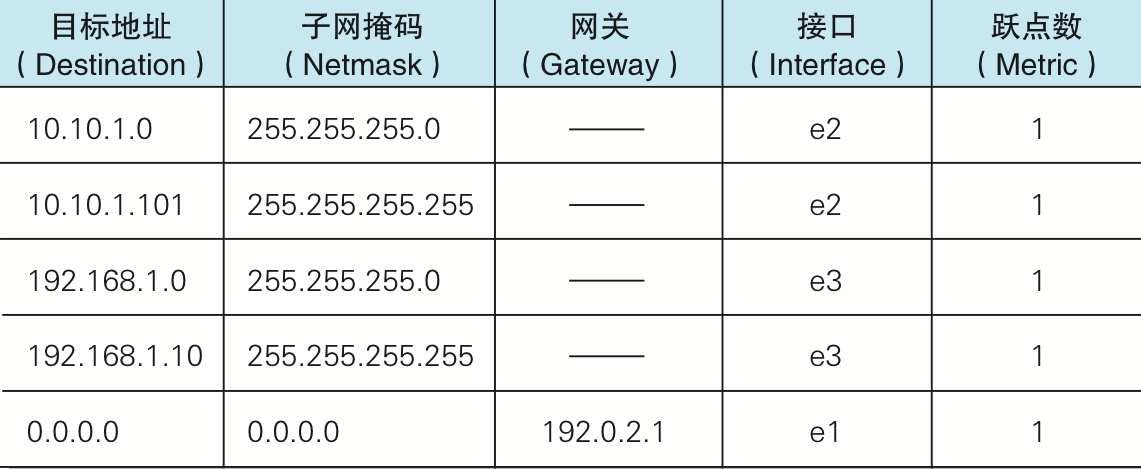
转发表由路由处理器计算生成和更新。转发表从路由处理器经过独立的总线复制到线路卡(Line Card),通过使用在每个输入端口的副本,转发决策就能在每个输入端口本地做出,无须每个分组都调用路由处理器来进行决策,从而避免了集中式处理的瓶颈 。查询转发表时,会忽略主机号,只根据子网掩码匹配 IP 地址的网络号 ,且采用 最长前缀匹配规则 (longest prefix matching rule) 。拿上图来说,目标地址为 192.168.1.10 的分组到达了路由器,然后将 192.168.1.10 和表中各 IP 地址分别与相应子网掩码进行与运算,若所得结果相同,则匹配。而计算后发现,图中 3、4、5 排记录都能匹配,根据最长前缀匹配规则,路由器最终匹配到网络号比特数最长的一条记录 (图中第4条)。网络号比特越长,说明子网中主机越少,从而减小了后续的寻找范围。需要注意的是,即使根据最长前缀匹配规则,我们仍然可能匹配到多条候选记录(例如考虑到路由器或网线故障而设置的备用路由),这时需要根据跃点数进行判断,跃点数越小则表明该路由越近。因此应该选择跃点数较小的记录 。若找不到匹配记录且不存在默认路由,路由器就会丢弃此分组,并通过 ICMP 消息告知发送方;若存在默认路由,则不匹配项都会被发送的默认路由 ;0.0.0.0 即为默认路由。
提高转发表查找速率是路由的核心问题之一。考虑具有 10 Gbps带宽的输入链路和 64 字节的 IP 数据报,其输入端口在另一个 IP 数据报到达之前仅有 51.2 纳秒的时间来处理数据报!所以实际网络对输入端口处理数据的速度要求极高,可以通过以下几个方面来提高速度:
- 采用硬件执行查找。硬件执行速率往往比软件执行速率高几个数量级。
- 提高查找算法的效率。
- 缩小转发表的规模。路由器会使用 CIDR 来减小转发表的条目数量,从而提高查询效率,详见笔者另一篇文章 [IP编址]。
- 提高内存访问速度。
除了上述的处理,输入端口还需要进行其他操作,比如检查 IP 首部的版本号、CheckSum 和 TTL ,并重写后两个字段:每经过一个路由,TTL 就需要自减一次,这是为了防止发生路由循环,TTL 初始值通常设为 64 或 128 ;由于 CheckSum 作用域包含了 TTL ,所以随着 TTL 的更新,CheckSum 也需要重新计算 。
交换结构(Switching Fbric)
确定好分组的输出端口后,就可以进入到路由器的交换结构。通过交换结构,分组才能由输入端口被转发到正确的输出端口。交换结构有如下三种方式:
.PNG)
- 内存交换: 最早的的路由器就是传统的计算机,交换直接由 CPU 控制。分组从输入端口被复制到内存中,然后 CPU 提取出目的 IP 地址并在表中进行查找合适的输出端口,然后再将该分组复制到相应的输出端口缓存中。这种方式效率较低,原因在于:(1)查找表都由 CPU 进行;(2)由于总线一次只能进行内存读/写操作,所以不能同时进行多个分组交换。许多现代路由器也采用经内存交换,但与早期路由器的一个主要差别是:转发表查找和将分组写入相应端口的内存是由线路卡来处理的。
- 总线交换: 输入端口经一根共享总线将分组直接传送到输出端口,其工作方式为:在输入端口为每个分组加上标签,然后经交换结构发送该分组至所有输出端口,但只有与该标签匹配的输出端口才会接收该分组;然后分组在输出端口去除标签并发送。相比于经内存交换,经总线交换无需路由处理器的干预,效率上有所提升;但由于每次只有一个分组能够跨越总线,所以交换带宽受总线速率限制,但对于网络边缘的路由器,总线速率通常够用。
- crossbar交换: 纵横式交换结构由 2N 条总线构成,它连接 N 个输入端口和 N 个输出端口。交叉点通过交换结构控制器(交换结构的一部分)进行开闭操作,当分组从 A 交换到 Y 时(A×Y交换),只需要开启总线 A 和 Y 之间的交叉点即可。通过这样的设计,crossbar 交换结构就能并行地转发多个分组 ,但并非任何时候都能执行并行转发,如下情况除外:(1)来自不同端口的多个分组有相同的目的端口。(2)(N×N)交换严格无阻塞,(M×N)交换可能发生阻塞;比如(A×X)与(B×Y)同时进行就会发生阻塞(交换路线交叉)。
设计交换网的时候一般要大于 1.2 倍的端口速率,这样才能保证在路由器内部交换网无阻塞的传输数据,这个 1.2 叫做加速比(speed up ratio),比如华为的NE5000E路由器的加速比是 2,所以可以实现交换网无阻塞的传输数据。
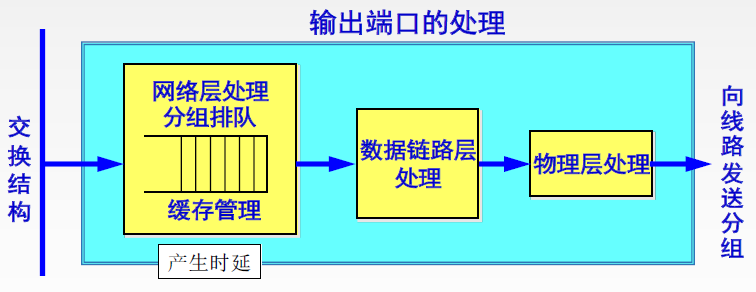
输出端口
输出端口取出其内存中的分组并将其发送到输出链路上。输出分组前可能面临排队和调度,相关内容见笔者另一篇文章《路由器中的排队与调度》。另外,在全双工模式下每个端口既是入端口也是出端口。其他操作相当于输入端口的逆操作,不再赘述。
路由处理器
-166082484083011.PNG)
路由处理器执行控制平面的功能,包括:执行路由选择协议、计算并下发路由表、网络管理等。路由处理器可以集成在路由器中,每个路由器独立地执行各自的路由算法和其他操作;也可以只负责与远程控制器进行通信,远程控制器收集整个网络的信息,并通过一根总线(上图虚线)下发转发表至各个路由器。这种集中式管理,控制平面与数据平面分开的方式称为 SDN(Software Defined Network) ,详细内容参见《通用转发与SDN》。
限笔者水平,文章难免有错误之处,如读者发现错误,敬请指出。
文章参考:《计算机网络自顶向下》,《网络是如何连接的》,CLOS架构





