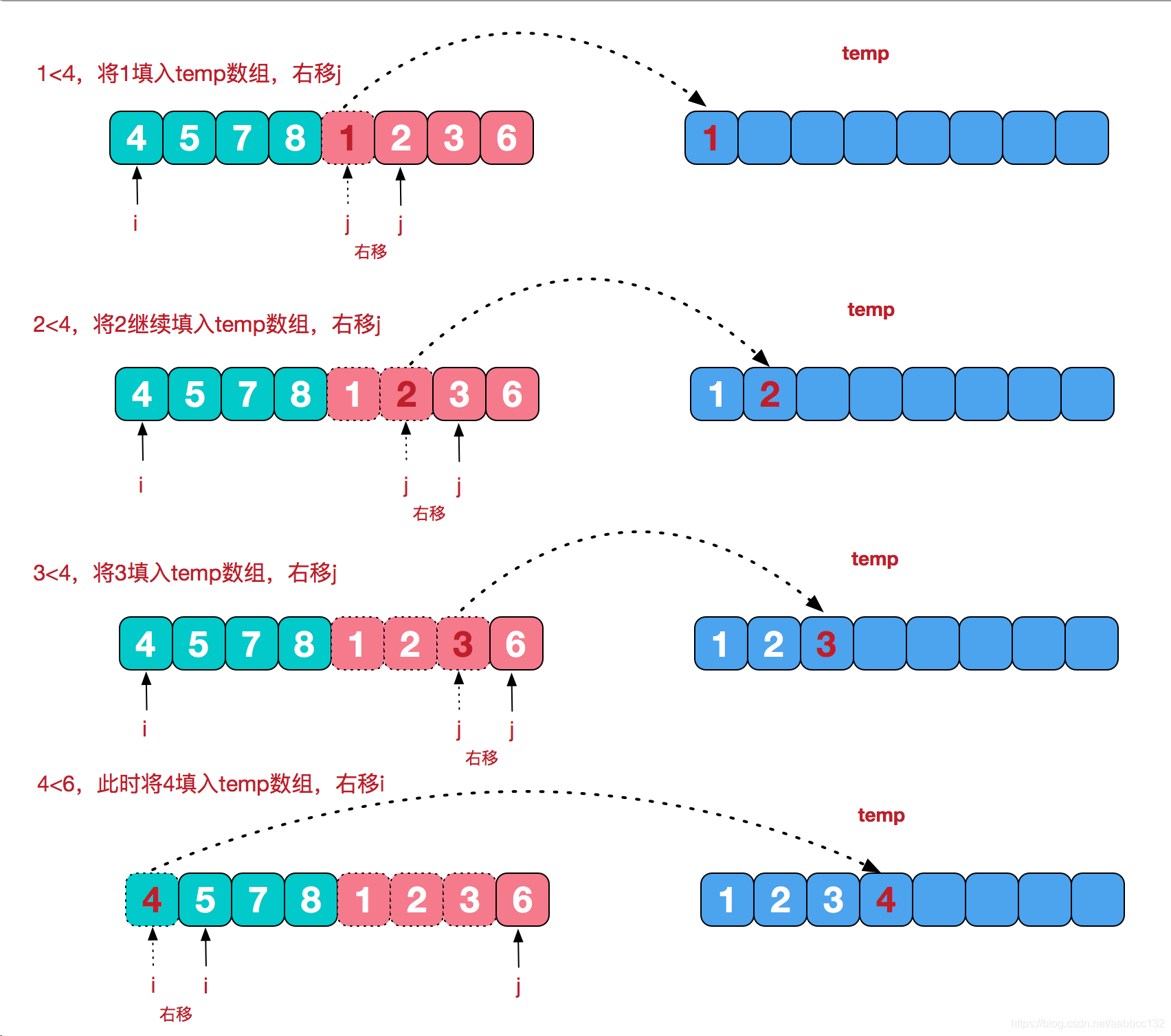
template<class T, class cmptor> voidmerge(T* vec, int l, int m, int r, cmptor cmp) { T* help = newint[r - l + 1]; int p = 0; //help[]的pointer int lp = l; //left pointer int rp = m + 1; //right pointer while (lp <= m && rp <= r) help[p++] = vec[lp] < vec[rp] ? vec[lp++] : vec[rp++]; while (lp <= m) help[p++] = vec[lp++]; while (rp <= r) //第10行和第12行的while只可能进入一个 help[p++] = vec[rp++]; for (int i = 0; i < r - l + 1; i++) vec[l + i] = help[i]; delete[] help; }
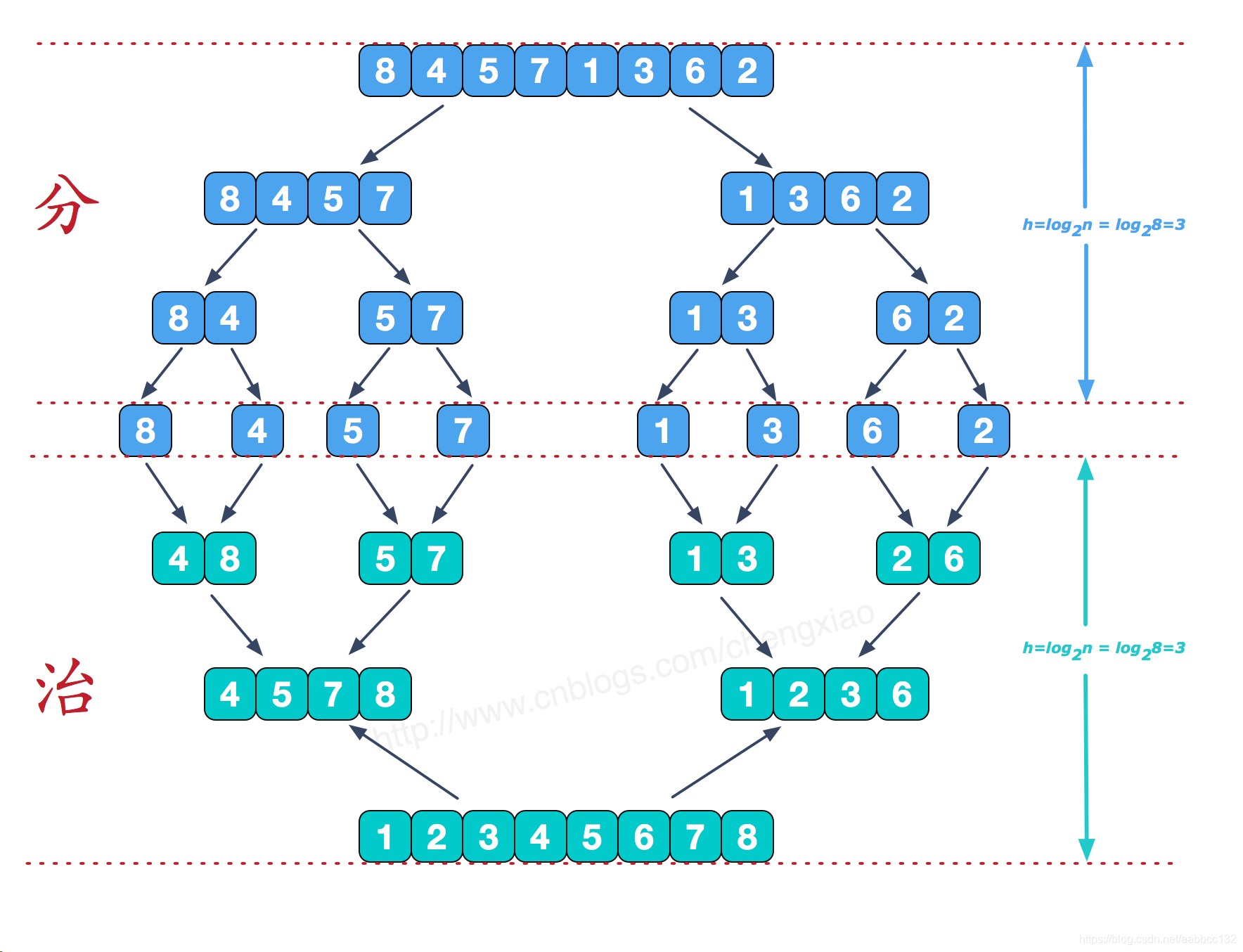
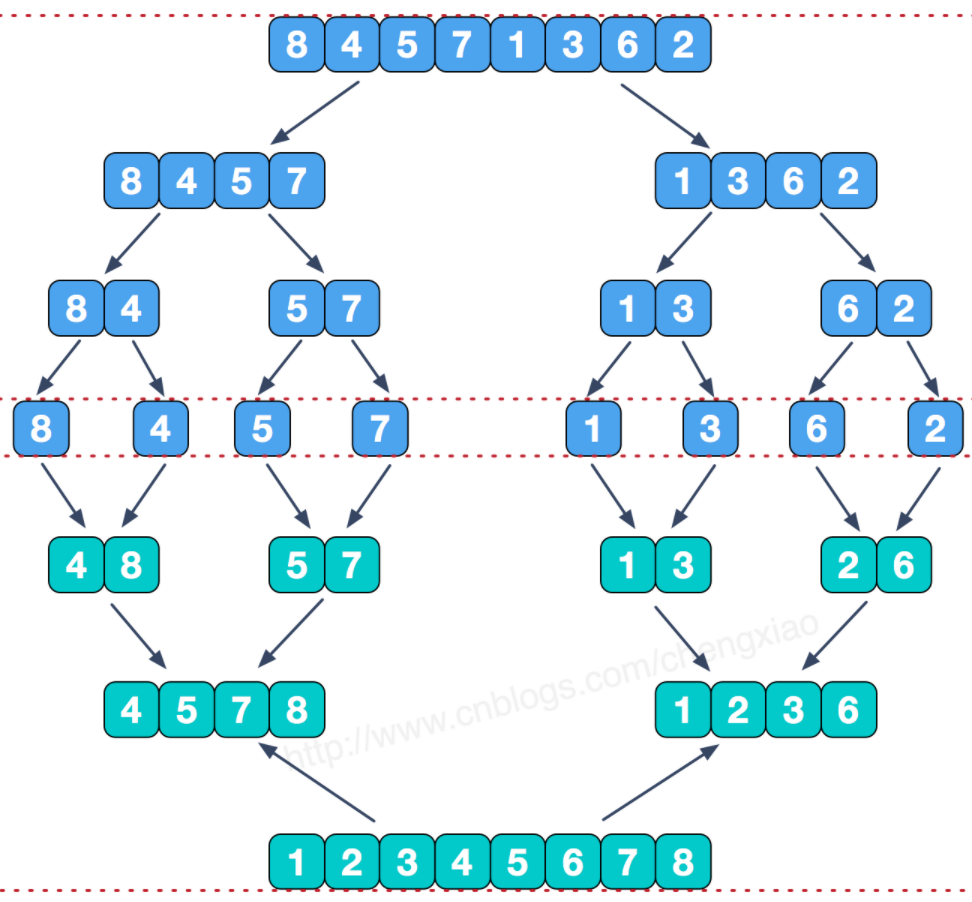
template<class T, class cmptor> voidprocess(T* vec, int l, int r, cmptor cmp) { if (l >= r)//base case return; int m = (l+r)/2; process(vec, l, m, cmp); process(vec, m + 1, r, cmp); merge(vec, l, m, r, cmp); } template<class T, class cmptor> voidmergeSort(T* vec, int size, cmptor cmp) { if (size == 1) return; int r = size - 1; process(vec, 0, r, cmp); }
voidmerge(int* arr, int l, int m, int r) { int* help = newint[r - l + 1]; int p = 0; int lp = l; int rp = m + 1; while (lp <= m && rp <= r) help[p++] = arr[lp] < arr[rp] ? arr[lp++] : arr[rp++]; while (lp <= m) help[p++] = arr[lp++]; while (rp <= r) //第9行和第10行的while只会进入其中一个 help[p++] = arr[rp++]; for (int i = 0; i < r - l + 1; i++) arr[l + i] = help[i]; delete[] help; }
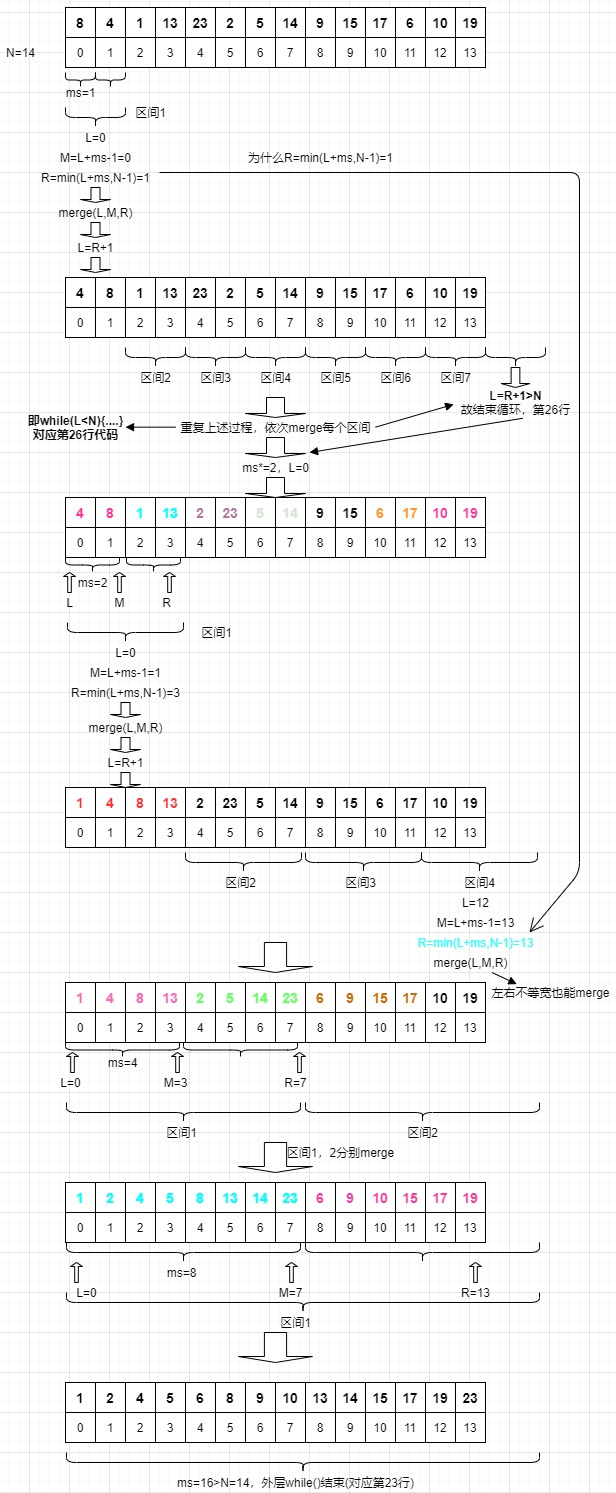
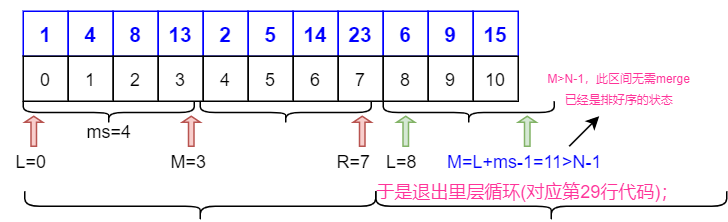
voidmergeSort(int* arr, int N) { if (arr == nullptr || N == 1) return; int mergeSize = 1, L, M, R; while (mergeSize < N) { L = 0; //极易忽略 while (L < N) { M = L + mergeSize - 1; if (M >= N-1) //极易忽略 break; R = (M + mergeSize) < (N - 1) ? M + mergeSize : N - 1; merge(arr, L, M, R); L = R + 1; } if (mergeSize > N / 2)//防止整形溢出 break; mergeSize *= 2; } }
intmain() { int arr[] = { 1,23,24,51,3,56,27,17,10,43,25,36,86 }; mergeSort(arr, sizeof(arr) / sizeof(int)); for (int i = 0; i < sizeof(arr) / sizeof(int); i++) { cout << arr[i] << " "; } }
迭代实现的 merge() 与递归实现的 merge() 相同
第 25 行极易忽略!
第 28 到 31 行代码的顺序很容易记错,其位置不可颠倒!!!
重点要讨论的边界处理,即第 23、26、29 行代码,其理由已经在图中详细阐述。
第 35 行代码十分容易忽略。当 N 靠近整形边界时,mergeSize×2 就可能发生溢出成为负数,然后回到第 23 行进行比较,又重新进入 while 循环!所以未来在这种作了增加运算后还要和其他数进行比较时,须特别注意这类情况!
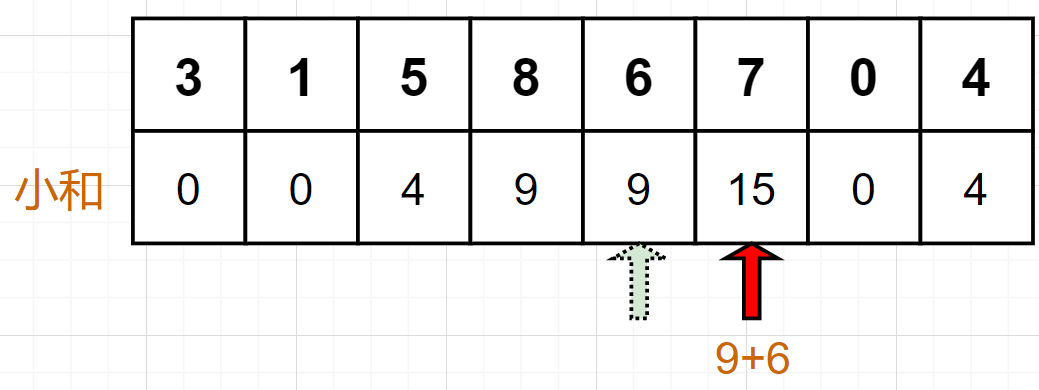
voidmerge(int* arr, int l, int m, int r) { int* help = newint[r - l + 1]; int p = 0; //help[]的pointer int lp = l; //left pointer int rp = m + 1; //right pointer while (lp <= m && rp <= r) { if (arr[lp] < arr[rp]) { count_1 += (r - rp + 1) * arr[lp];// } help[p++] = arr[lp] < arr[rp] ? arr[lp++] : arr[rp++]; } while (lp <= m) help[p++] = arr[lp++]; while (rp <= r) //第9行和第11行的while只可能进入一个 help[p++] = arr[rp++]; for (int i = 0; i < r - l + 1; i++) arr[l + i] = help[i]; delete[] help; }
voidprocess(int* arr, int l, int r) { if (l == r)//base case return; int m = l + ((r - l) >> 1); process(arr, l, m); process(arr, m + 1, r); merge(arr, l, m, r); }
voidmergeSort(int* arr, int size) { if (size == 1) return; int r = size - 1; process(arr, 0, r); }
voidmerge(int* arr, int l, int m, int r) { int* help = newint[r - l + 1]; int p = 0; //help[]的pointer int lp = l; //left pointer int rp = m + 1; //right pointer while (lp <= m && rp <= r) { if (arr[lp] > arr[rp]) { count_1 += r - rp + 1; } help[p++] = arr[lp] > arr[rp] ? arr[lp++] : arr[rp++]; } while (lp <= m) help[p++] = arr[lp++]; while (rp <= r) //第9行和第11行的while只可能进入一个 help[p++] = arr[rp++]; for (int i = 0; i < r - l + 1; i++) arr[l + i] = help[i]; delete[] help; }
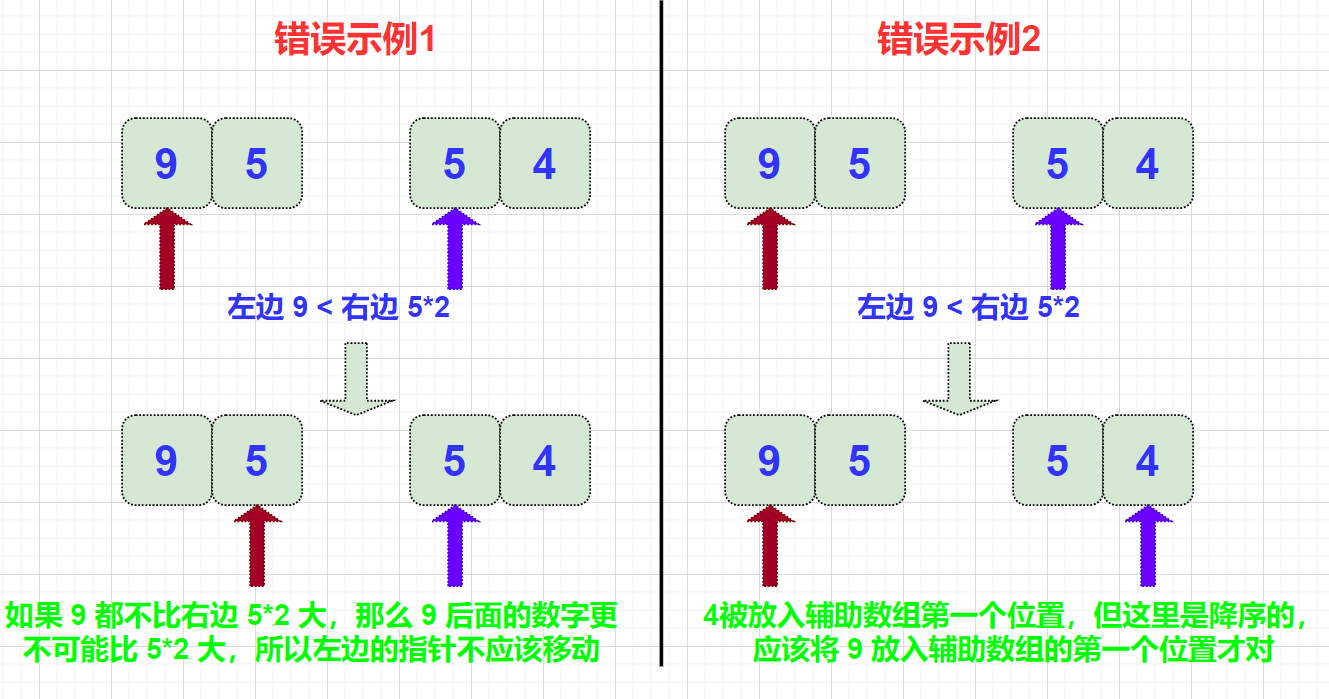
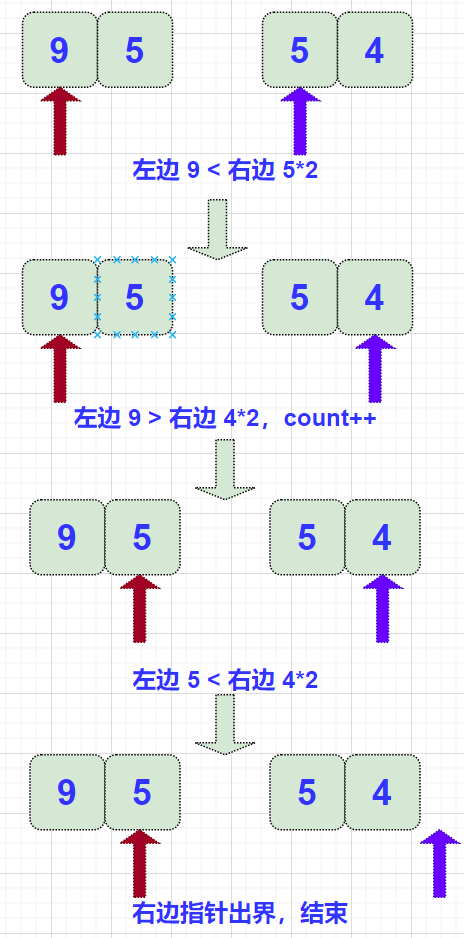
voidmerge(int* arr, int l, int m, int r) { int lp = l; int rp = m + 1; while (rp <= r && lp<=m) { if (arr[lp] > (arr[rp] * 2)) { count_1 += r - rp + 1; lp++; } else rp++; }
int* help = newint[r - l + 1]; int p = 0; //help[]的pointer lp = l; //left pointer rp = m + 1; //right pointer while (lp <= m && rp <= r) { help[p++] = arr[lp] > arr[rp] ? arr[lp++] : arr[rp++]; } while (lp <= m) help[p++] = arr[lp++]; while (rp <= r) //第9行和第11行的while只可能进入一个 help[p++] = arr[rp++]; for (int i = 0; i < r - l + 1; i++) arr[l + i] = help[i]; delete[] help; }
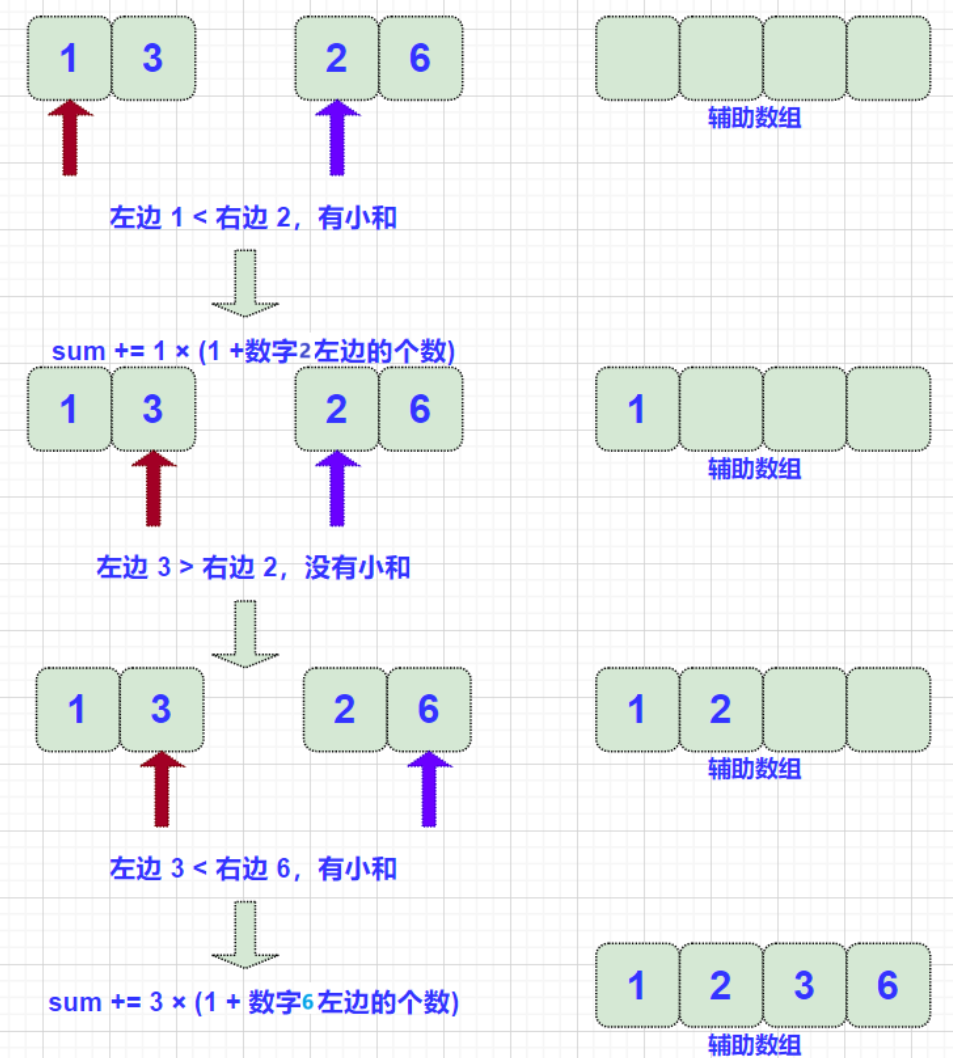
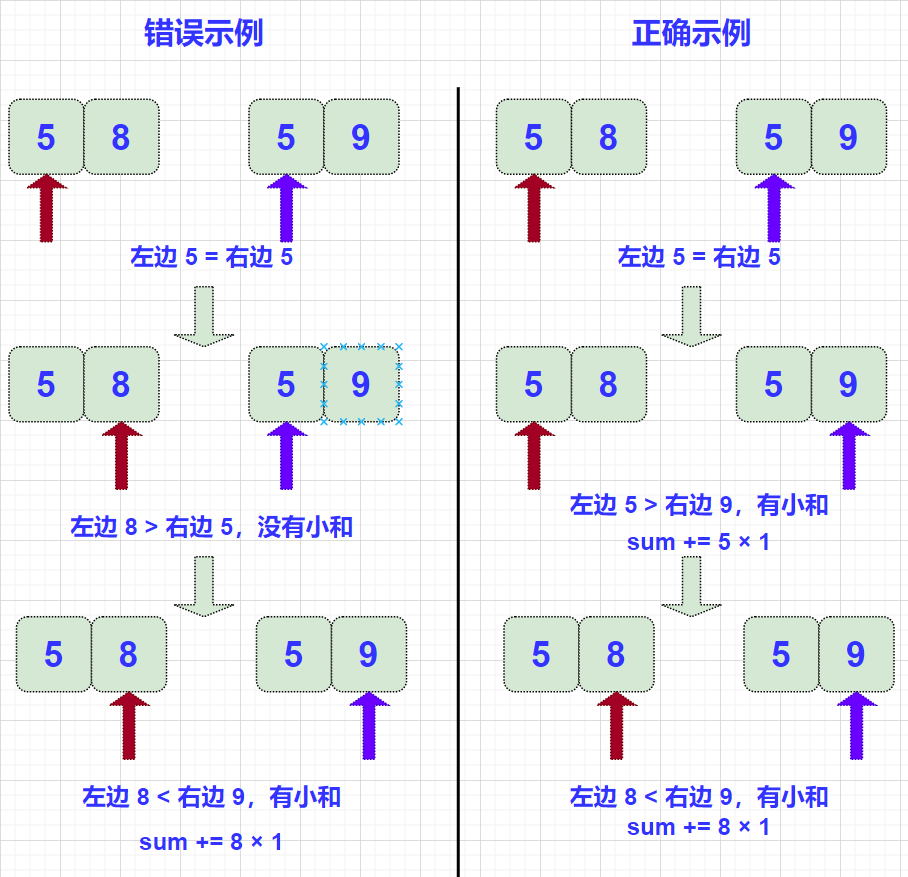
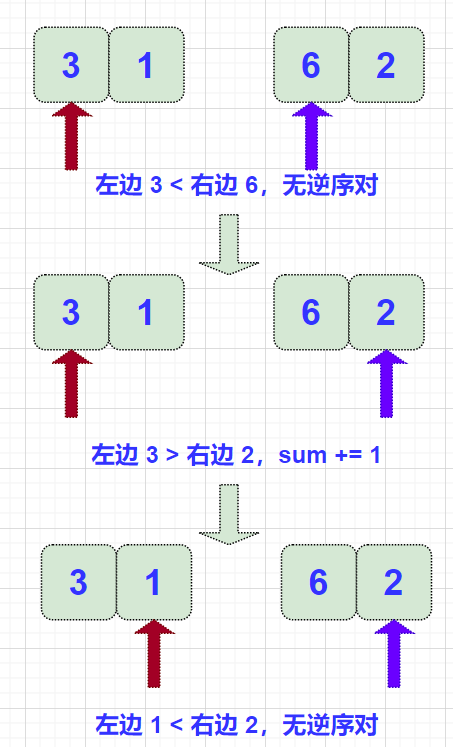 对 merge() 稍作修改即可:
对 merge() 稍作修改即可: