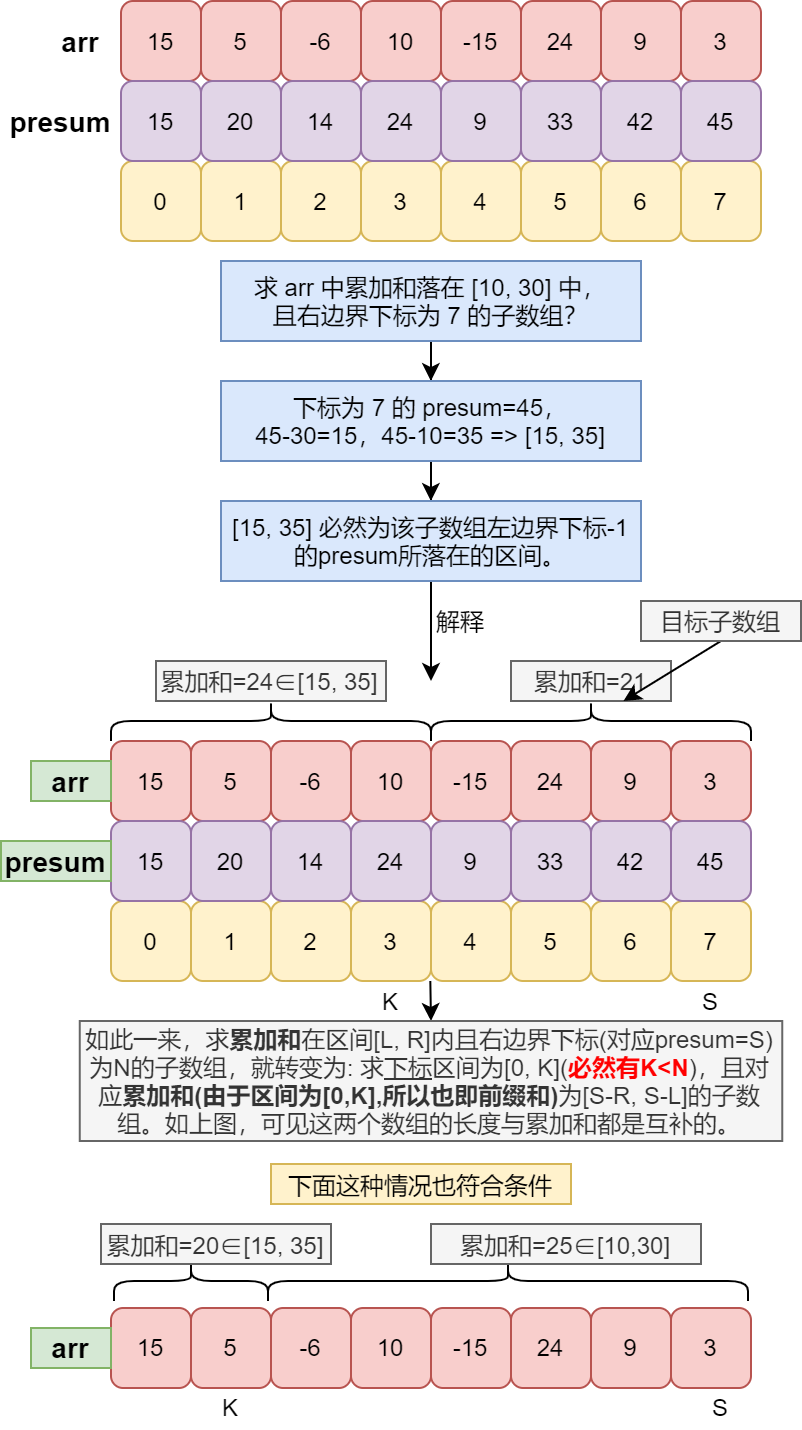
voidmerge(int* arr, int l, int m, int r) { int lp = l; //left pointer int rp = m + 1; //right pointer while(rp<=r) { int prel = arr[rp] - upper;//presum left int prer = arr[rp] - lower;//presum right while (true) { if (lp > m) { rp++; lp = l; break; } if (arr[lp] < prel) lp++; elseif (arr[lp] > prer) { rp++; lp = l; break; } else { cnt++; lp++; } } }
int* help = newint[r - l + 1]; int p = 0; //help[]的pointer lp = l; rp = m + 1; while (lp <= m && rp <= r) help[p++] = arr[lp] < arr[rp] ? arr[lp++] : arr[rp++]; while (lp <= m) help[p++] = arr[lp++]; while (rp <= r) //第9行和第11行的while只可能进入一个 help[p++] = arr[rp++]; for (int i = 0; i < r - l + 1; i++) arr[l + i] = help[i]; delete[] help; }
voidprocess(int* arr, int l, int r) { if (l == r)//base case { if (arr[l] >= lower && arr[r] <= upper) cnt++; return; } int m = l + ((r - l) >> 1); process(arr, l, m); process(arr, m + 1, r); merge(arr, l, m, r); }
voidmergeSort(int* arr, int size) { if (size == 1) return; int r = size - 1; process(arr, 0, r); }
intmain() { lower = 10; upper = 30; int arr[4] = {10,1,1,10}; int presum[4] = {0}; //10 11 12 22 for (int i = 0; i < 4; i++) { for (int k = 0; k <= i; k++) presum[i] += arr[k]; } mergeSort(presum,4); std::cout << cnt << std::endl; }
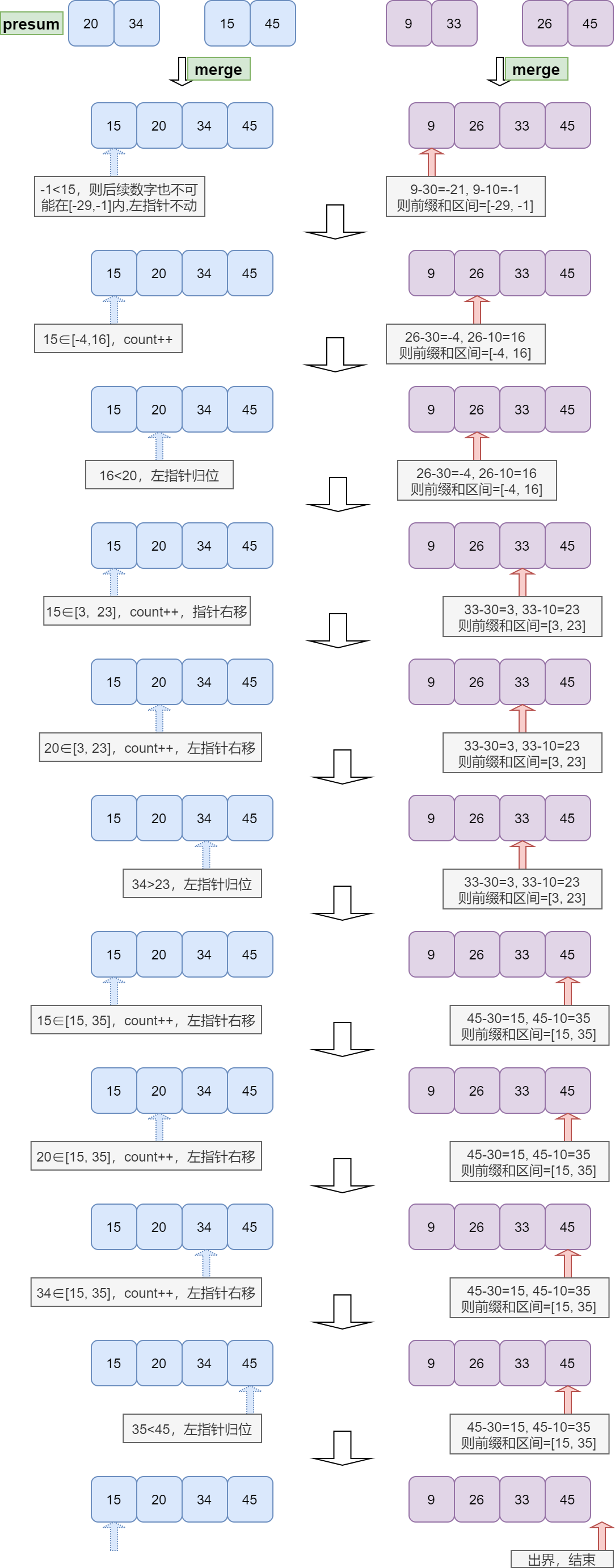
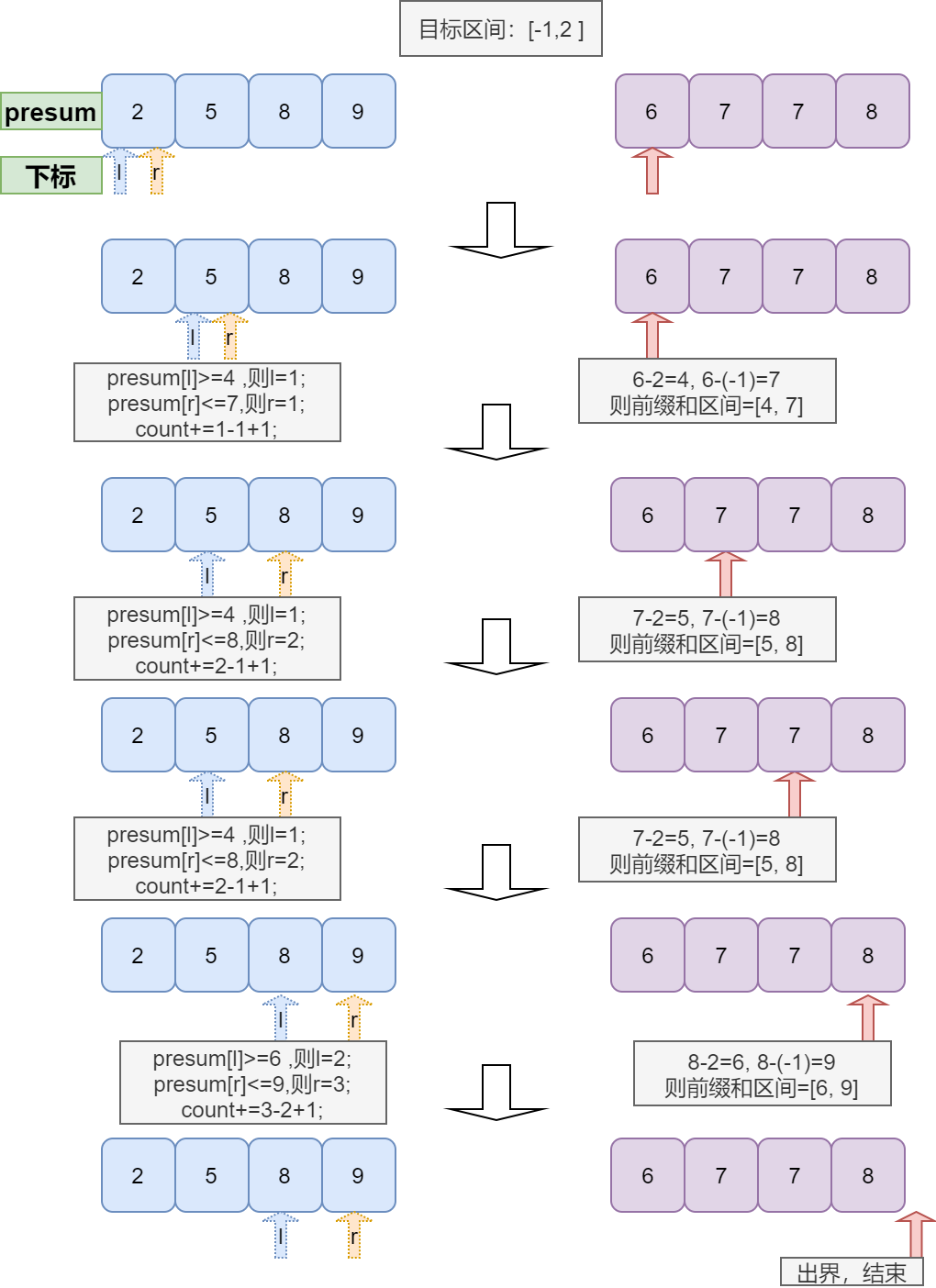
voidmerge(int* arr, int l, int m, int r) { int lp = l; int rp = m + 1; int wl = l - 1; //window left; wl即图中的l int wr = l - 1; //window right; wp即图中的r while(rp <= r) { int prel = arr[rp] - upper;//presum left int prer = arr[rp] - lower;//presum right while (wl <= m) { if (arr[wl] < prel) wl++; elsebreak; } if (wl > m) break; while (wr <= m) { if (arr[wr + 1] <= prer && wr!=m) wr++; else break; } if (wl != l-1 && wr != l-1) cnt += wr - wl + 1; rp++; }
int* help = newint[r - l + 1]; int p = 0; //help[]的pointer lp = l; rp = m + 1; while (lp <= m && rp <= r) help[p++] = arr[lp] < arr[rp] ? arr[lp++] : arr[rp++]; while (lp <= m) help[p++] = arr[lp++]; while (rp <= r) //第9行和第11行的while只可能进入一个 help[p++] = arr[rp++]; for (int i = 0; i < r - l + 1; i++) arr[l + i] = help[i]; delete[] help; }
voidprocess(int* arr, int l, int r) { if (l == r)//base case { if (arr[l] >= lower && arr[r] <= upper) cnt++; return; } int m = l + ((r - l) >> 1); process(arr, l, m); process(arr, m + 1, r); merge(arr, l, m, r); }
voidmergeSort(int* arr, int size) { if (size == 1) return; int r = size - 1; process(arr, 0, r); }
intmain() { lower = 10; upper = 30; int arr[4] = {0,9,-1,-1}; int presum[4] = {0}; //10 20 30 40 for (int i = 0; i < 4; i++) { for (int k = 0; k <= i; k++) presum[i] += arr[k]; } mergeSort(presum,4); std::cout << cnt << std::endl; }