
汇编语言入门
什么是汇编语言?
我们最初学习编程时,一般都是学习高级语言,诸如 C++,Java,Python 等,通过一定语法编写代码,然后运行,代码就能够顺利地在电脑中跑起来。但是,计算机实际上并不认识高级语言,它只认识如 01011001 这样的二进制数字。0,1 虽然简单,但无数个代表着高低电平的 0 和 1 组合却能指挥计算机完成几乎所有你能想到的任务。
早期的程序是由科学家们手工编写二级制代码完成的,面对巨量的,毫无规律的 0 和 1,其工作量可想而知。为了解决这一窘况,汇编语言应运而生。其实, 汇编语言严格来说并不是一门语言,而仅仅只是一套助记符,它与二进制代码一一对应 。如下图,汇编语言与人类语言更为接近,便于阅读和记忆。
汇编语言直接运行于硬件之上 。由于 CPU 硬件设计和内部架构的不同,其对应的指令集(机器语言)也不同,每一种 CPU 都有自己的汇编指令集 。 所以,汇编语言依赖于硬件体系,不便于移植 。对于同一个程序,如果在这台机器上可以运行,而到另一台机器上就必须重新改写某些代码以适应机器,那这样就太麻烦了。再之,汇编代码只比机器代码容易阅读了一点而已,理解起来还是很困难。
汇编语言的种类
从汇编格式上: 分为 Intel 和 AT&T 两种风格,两者是 X86 架构的不同写法。Intel 格式和 AT&T 格式的区别只是符号系统的区别 。前者常见于 Windows,masm 仅支持 Intel;而 AT&T 在 Unix 中更常见,GNU 汇编器的默认格式就是 AT&T。
从架构体系上: 分为 复杂指令集(CISC) 和 精简指令集(RISC) ,前者的代表是 X86架构 ,后者代表是 ARM 架构。RISC 多用于移动端,全世界超过95%的智能手机和平板电脑都采用 ARM 架构;CISC 多用于 PC 端和服务器端,苹果的 PC 机使用的 CPU(M1) 是 ARM 架构。
汇编语言的组成
- 汇编指令 ,如
mov,有对应的机器码。 - 伪指令 ,如
segment和end,由汇编器识别,没用机器码,计算机不执行。 - 其他符号 ,如
+、-等,由汇编器识别,没有机器码。
汇编指令是汇编语言的核心。 其中,伪指令根据编译器的不同而有所变化。
CPU总线
CPU 读写硬件中的数据时,必须经过下面三类信息的交互:
- 地址信息 :储存单元的地址
- 控制信息 :选择器件,读或写的命令.
- 数据信息 :读或写的内容。
以上三种信息分别由 地址总线、控制总线、数据总线 传递。总线将 CPU 与其他芯片连接起来。以下是 CPU 从地址为 3 的内存中读取数据的过程:
.PNG)
- CPU 通过地址线将位置信息发送给内存
- CPU 通过控制线向内存发送读命令,选中储存器芯片,并通知它将从内存读取数据。
- 储存器将相应位置的数据通过数据线传送给 CPU。
总线的宽度: 一根导线上只能传送两种状态:低电平与高电平,对应着 0 和 1;那么 32 根导线一次传送的最大数据为 。总线所包含的导线数目即为总线宽度。
地址总线的宽度代表着 CPU 的寻址能力,即最多能用多少内存;数据总线的宽度决定了 CPU 对数据的读写能力,平时我们说的 32/64 位机器,指的就是机器的数据总线宽度(寄存器的宽度);控制总线的宽度决定了 CPU 对外部器件的控制能力。
8080,8088,80286,80386 的地址总线宽度分别为 16,20,24,32,则它们的寻址能力分别为:64KB,1MB,16MB,4GB 。
硬件概览
主板
主板上有核心器件(CPU,储存器等)和一些主要器件(外围芯片组,扩展插槽等),这些器件通过总线相连。
接口卡
所有可被程序控制的硬件设备都必须受到 CPU 控制。但 CPU 不能直接控制这些设备,直接控制设备的是接口卡,而 CPU 通过总线与接口卡相连,利用接口卡来间接控制设备。简单来说,CPU 通过总线向接口卡发送命令,接口卡根据收到的命令来指挥设备工作。
储存器芯片
从读写属性上分为两类:
- ROM (Read Only Memory) ,随机储存器可写可读,但必须带电储存,关机后数据丢失;
- RAM (Random Access Memory) ,只读储存器只可读,关机后内容不丢失;
从功能上大概分为以下几类:
- 随机储存器 :用于存放供 CPU 使用的绝大部分程序和数据。主随机储存器一般由主板上的 RAM 和扩展插槽上的 RAM 组成。
- 装有 BIOS (Basic IO System) 的 ROM :BIOS 是由主板和各类插口卡(网卡、显卡等)厂商提供的系统软件,通过它来利用该设备进行最基本的输入输出。主板上的 ROM 存储着系统 BIOS ;显卡上的 ROM 中储存着显卡的 BIOS;网卡中的 ROM 存储着网卡的 BIOS。机器加电后,启动 BIOS 程序进行一系列的机器初始化动作,然后装入操作系统的初始文件,引导操作系统启动 。BIOS是固化在硬件的一种程序 。BIOS 中包含以下内容:
- 硬件系统的检测和初始化程序。
- 外部中断和内部中断的中断例程。
- 对硬件设备进行 I/O 的中断例程。
- 其他和硬件系统相关的中断例程。
- 接口卡 :某些接口卡需要对大批量的输入输出进行储存,其上就会装有 RAM。最典型的就是显卡上的 RAM (显存)。显卡随时将显存中的数据向显示器输出,所以我们才能看见屏幕上的内容。
.PNG)
工作模式
8086/8088 CPU 为单任务操作系统,可以直接操控内存,是不安全的。Intel 进而推出 80286,具备了对多任务系统的支持,首次提出了保护模式的概念。80286 拥有 24 根地址线,可访问 16 MB 的内存,其 16 位段寄存器中也不再存放段地址,而是存放段选择子,真正的段地址位于描述符高速缓存中;其偏移地址最大仍为 64 KB,这是很大的缺陷。而后来的 80386 是划时代的,拥有 32 根地址线,可访问 4 GB 内存;其段偏移量也是 32 位的,在最典型的情况下,可以将 4GB 当作一个段来使用,即平坦模型。它支持以下三个模式:
- 实模式:相当于一个 8086
- 保护模式:多任务环境,建立保护机制。
- 虚拟 8086 模式:可以从保护模式切换到实模式,这种方式方便用户在保护模式下运行 8086 程序。
80286 CPU 的缺陷在于,它只提供实模式和保护模式,没有提供虚拟模式,这很不利于用户的工作。
内存地址空间
利用接口卡与主储存器,CPU 便能够将所有硬件抽象成内存,通过修改内存来完成对各类硬件的控制! 将所有储存器看作一个由若干储存单元组成的逻辑储存器,这个逻辑储存器就是我们常说的内存地址空间。
.PNG)
每个物理储存器都在这个地址空间中占有一定位置,CPU 在这个位置上读写数据,实际上就在对应的物理储存器中读写数据。
实模式内存分布如下:
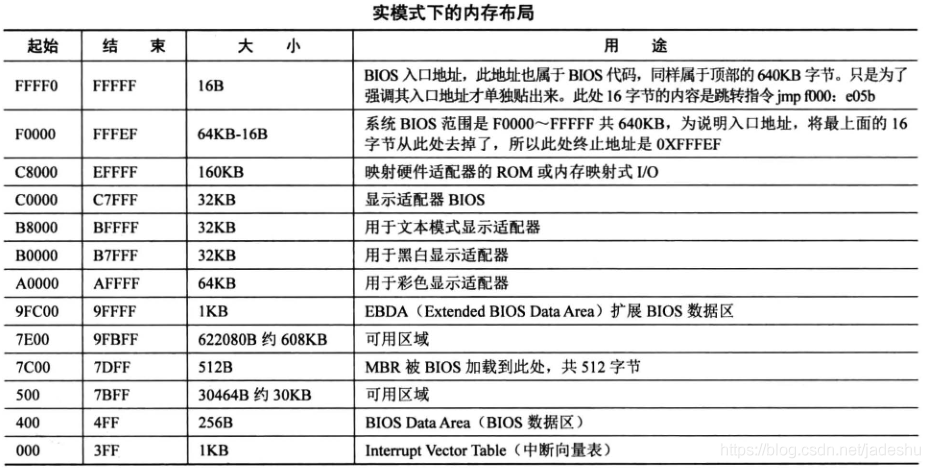
一般而言,如果需要向内存空间写入数据的话,要使用操作系统给我们分配的空间,而不应直接用地址任意指定内存单元向里面写入,这可能导致程序的崩溃。注意,我们在纯DOS方式(实模式)下,可以不理会DOS,直接用汇编语言去操作真实的硬件,因为运行在CPU实模式下的DOS没有能力对硬件系统进行全面、严格的管理。但在Windows 2000、Unix这些运行于CPU保护模式下的操作系统中,不理会操作系统,用汇编语言去操根本不可能的,硬件已被这些操作系统利用CPU保护模式所提供的功能全面而严格地管控 。
在DOS中,0:0200~0:02FF 这段 256 字节的空间一般为空闲,可随意使用。
数据表示
- 字节:8 bits;字节是计算机的最小操作单元,比特是最小存储单元。
- 字:2 字节,即 16 bits;由高位字节和低位字节组成,高低位指的是数据的高低位,而非地址的高低。
- 常用表示:,,,
- 一个两位十六进制数可以使用一个字节储存,一个四位十六进制数可以用两个字节存储,以此类推。比如 AX 中存放 0XFFEE,那么 AH 中为 0XFF,AL 中为 0XEE。这种方式可以很容易地看出数据的组成,利于直观分析。
- 在小端机器中,低地址存放字型数据的低位数据,高地址存放字型数据的高位数据。
8086寻址方案
8086 CPU有 20 位地址总线,达到 1 MB寻址能力,所以内存空间也只有 1MB 。但 8086 CPU是 16 位结构,即,其寄存器最大宽度为 16 位 (或者说,其运算器一次最多可以处理16位数据,寄存器和运算器之间的通路为16位) ,所以如果只是简单发出地址,那么只能一次性处理或存储 16 位地址。所以,8086 使用两个 16 位地址合成一个 20 位物理地址 ,即 物理地址=段地址×16+偏移地址,其中,段地址×16又叫做基础地址 。
.PNG)
有几点需要注意:
- 乘 16 即右移 4 位。
- 段地址×16 必然是 16 的倍数,所以段起点必然也为 16 的倍数,比如 10010H。
- 一个物理地址可能由多种运算得到,比如,10010H 可能由 1001H×16+0 得到,也可能由 1000H×16+0010H得到。
- 由于偏移地址为 16 位,所以一个段的最大长度为 64KB
- 段始终以 16 字节对齐 ,如果 data 段只有 14 字节,范围为 1001:0 ~ 10001:D,code 段也会从 1002:0 开始。
内存定位的多种方式
.PNG) 注意:
注意:
-
在 [ ] 中,BX/SI/DI/BP 可以分别单独出现;
-
或只能以四种组合出现:BX 与 SI,BX 与 DI,BP 与 SI,BP 与 DI;
这样理解:BX 与 BP 为基址寄存器,DI 与 SI 为变址寄存器。
-
只要含 BP,默认段寄存器就为 SS ;
plaintext1
2
3#错误方式:
mov ax,[bx+bp]
mov ax,[si+di]
指令的执行过程
-
从 CS : IP 指向的内存单元读取指令,将指令送入指令缓冲器。
指令缓冲器可防止高速处理器在数据传输序列期间被锁定到慢速 I/O 设备,或减少较快和较慢设备之间的速度不匹配 。
-
IP = IP + 所读指令的长度,从而指向下一条指令。
容易发现,指令的长度是可变的,那么 CPU 如何判断指令的长度呢?对于可变长编码,我们应该可以想到一条思路:每个指令的机器码都不可能是其他机器码的前缀。
-
执行指令。然后转到步骤一,重复以上过程。
指令从低到高地址依次执行。
中断
内中断
内中断分为软中断和异常 ,指的是 CPU 本身执行当前指令时所发生的中断。内中断具体分为: 1)由软中断指令 int 启动的中断;2)在一定条件下由 CPU 自身启动的中断(异常) 。当 CPU 内部发生以下情况时,会发出中断信息:
-
除法错误
-
单步执行
-
执行 into 指令
本指令检测 OF 标志位,当 OF=1 时,说明已发生溢出,立即产生一个中断类型为 4 的中断,当 OF=0 时,本指令不起作用。本指令可用于溢出处理,影响 TF 和 IF 标志位。
-
执行 int 指令
指令格式为 int N,N 是字节型立即数,为中断码。
中断向量表
CPU 用中断类型码来标识中断信息,中断码长度为 1 字节,可表示 256 中断信息。
CPU 侦测到中断码后,根据 中断向量表 ( IVT ) 找到中断码对应的中断处理程序入口地址,并放入 CS:IP 中,执行程序。 中断向量表在开机时由 BIOS 程序加载进内存,并放在 0000:0000 ~ 0000:03ff 这 1024 个字节中,其中 0000:0200~0000:02ff这256字节一般为空闲 。中断向量表是PC系统中最重要的内存区。中断向量表每个表项长 4 字节,所以中断向量表最多有 256 个中断信息。
DOS 也提供中断例程。BIOS 完成硬件检测和初始化后,调用 int 19h 进行操作系统的引导,从此将计算机交给操作系统。DOS 启动后,将自己提供的中断例程载入内存,并建立响应中断向量表项。DOS 只有 int 21h 一个例程,但可以根据 ah 中的功能号调用子功能,这就是为什么程序返回指令为
mov ax,4c00和int 21h。
中断过程
用中断码 N 找到中断向量,并用它设置 CS:IP,这个过程由 CPU 硬件自动完成 ,此过程被称为中断过程。由于处理完中断后,之前的程序应该恢复,所以执行中断前需要保存 CPU 现场(保存标志寄存器即可,其他寄存器会在中断处理内部保存)。中断过程如下:
- 取得中断码 N
- pushf
- TF=0,IF=0
- push CS
- push IP
- IP=N×4,CS=N×4+2
以上过程由 cpu 硬件自动完成,无需人为干预。
中断处理程序规范
- 保存用到的寄存器
- 处理中断
- 恢复用到的寄存器
- iret
响应中断的特殊情况
有些情况下,CPU 执行完当前指令后,即使发生中断,也不会响应。比如,向 SS 寄存器传送数据后,就算发生单步中断,CPU 也不会响应。原因是 SS:SP 联合指向栈顶,对它们的赋值应该连续完成,即,向 SS 赋值后,应立即向 SP 赋值,否则一旦 SS 赋值后发生中断, SS:SP 就指向了错误的栈顶,将引起错误。
int中断
int n 调用中断码为 n 的中断过程。int 和 call 类似,都是调用一段程序。系统将某些子程序以 int 中断的方式提供给应用程序调用。比如程序返回指令:
1 | mov ax,4c00h |
外中断
CPU 通过外中断来处理外设引发的事件。 外中断分为可屏蔽中断和不可屏蔽中断,IF 只对外中断有效 :当 IF=1,进入中断程序后,允许转向可屏蔽中断;IF=0则不可。遇上不可屏蔽中断,无论 IF 为多少,都转向不可屏蔽中断。几乎所有外中断都是可屏蔽中断,电源断电等引起不可屏蔽中断。
端口
什么是端口
CPU 可以直接从以下三个地方直接读取数据:
- CPU 内部寄存器
- 内存单元
- 端口
前两者我们已经很清楚,那么端口是什么呢?端口是各种接口芯片上可供 CPU 读写的寄存器。CPU 将不同接口芯片的寄存器映射在内存中,形成统一的端口地址空间,这样就方便了对端口的读写。CPU 通过读写端口或内存映射来间接访问硬件。关于端口更详细的讨论,见 端口详解 。
读写端口
使用 in 和 out 指令读写端口,且只能使用 AX 或 AL 存放从端口读入或要输出到端口的指令,访问 8 位端口用 AL,16 位端口用 AX:
1 | #从60h号端口读数据,传送给al寄存器 |
寄存器用法总结
8086 CPU 中所有寄存器都是 16 位,而 8086 上一代 CPU 中寄存器都为 8 位, 为了保证兼容,使基于上一代 CPU 编写的程序稍加修改就能运行于 8086 之上,8086 CPU 中的通用寄存器(AX, BX, CX, DX)都可以分为两个可独立使用的 8 位寄存器。
通用寄存器
8 个通用寄存器:AX、BX、CX、DX、SI、DI、SP、BP ;下面列出这几个寄存器的名字,以展现其常见用途:
AX :累加器(Accumulator);
BX :基地址寄存器(Base Register);
CX :计数寄存器(Count Register);
DX :数据寄存器(Data Register);
SI : 源索引寄存器(Source Index Register);
DI :目标索引寄存器(Destination Index Register);
BP :基址针寄存器(Base Pointer Register);
SP :栈指针寄存器(Stack Pointer Register);
AX , BX , CX , DX 常用来存放一般性数据。它们可以分为两个独立的寄存器 ,比如 AX 可分为 AH 和 AL,BX 可分为 BH 和 BL,其他同理。注意,H 指数据高位,L 指数据低位,而非地址的高低。当数据溢出时,舍弃高位。
SI , DI , SP , BP 常用于寻址操作。它们不可分为两个独立的寄存器 。
其中寄存器的专门用法为:
- AX:
- 存放被除数 :如果除数为 8 位,则被除数须为 16 位,放在 AX 中;如果除数为 16 位,则被除数须为 32 位,高位放在 DX 中,低位放在 AX 中。
- 存放商 :如果除数为 8 位,则将商放入 AL,余数放入 AH;如果除数为 16 位,则将商放入 AX,余数放入 DX。
- 存放乘数与积 :若为 8 位乘法,其中一个乘数放在 AL 中,结果放在 AX 中;若为 16 位,其中一个乘数放在 AX 中,结果高位放在 DX 中,低位放在 AX 中。
- 常用作累加器和返回值 。
- BX:[ ] 中只能为立即数、BX、SI 、DI 或 BP 。利用 Loop 和 [BX/SI/DI/BP] 可以方便地完成对内存的连续操作。 但注意 [BX/SI/DI] 的默认段寄存器为 DS;[BP] 默认的段寄存器为 SS;
- CX:大多与循环或者条件判断相关,比如:
- Loop 的循环计数器
jcxz指令的条件判断寄存器。- 控制
rep指令的循环次数。 - CL 存放 shl 和 shr 的位移。
- DX:被用来放整数除法产生的余数,见 AX;
- SI :见 BX;在很多字符串操作指令中, DS:SI 指向源串,而 ES:DI 指向目标串。
- DI :见 BX,SI;用 DI 与 SI 可实现多种存储器操作数的寻址方式,为以不同的地址形式访问存储单元提供方便。
- BP:见 BX; BP 的作用之一就是在栈中找到函数的形参,栈中的局部变量也是通过 BP 来定位的 ;
- SP:[SP] 永远指向栈顶, [SP] 的默认段寄存器为 SS ;BP 和 SP 都和栈相关。
段寄存器
CS , DS , SS , ES
-
CS:代码段寄存器,配合 IP 寄存器使用。
-
DS:数据段寄存器,其偏址寄存器只能为:BX,BP,SI,DI。 [BX/SI/DI] 的默认段寄存器为 DS ,如下:
plaintext1
mov ax,[0]
-
SS:栈段寄存器,配合 SP 寄存器使用。任意时刻,SS : SP 指向栈顶元素 。
-
ES:附加段寄存器。作用与 DS 差不多,DS 偏指数据来源段,ES 偏指数据输出段 ,比如源字符串和目标字符串,详见 movsb 的使用。
8086 CPU 不支持将数据直接送入段寄存器,必须通过寄存器将数据送入段寄存器;也不能直接在段寄存器上做运算 ;
标志寄存器
flag 寄存器是按位起作用的,其中每一位都有不同的含义:

- ZF:零标志位。它记录相关指令( add、sub、mul、div、inc、or、and 操作)执行后,结果是否为0 。ZF = 1结果不为0,ZF = 0结果为0。
- PF:奇偶标志位。它记录指令执行后,结果的所有二进制位中 1 的个数是否为偶数,如果为偶数则 PF = 1,为奇数,PF = 0。
- SF:符号标志位。它记录指令执行后,结果是否为负(就是看它二进制的第一位是不是1),如果为负数则SF = 1,结果为正,SF = 0。
- CF:进位标志位。在进行 无符号数运算 的时候,它记录了运算结果的最高有效位是否向更高位进位,或从更高位借位。
- OF:溢出标志位。OF记录了 有符号数运算 的结果是否发生了溢出。如果发生溢出,OF=1,如果没有,OF=0。
- DF:方向标志位。配合串传送指令 movsb,movsw 等使用。cld 指令将 DF 置为 0,则正向传送;std 将其置为 1,则反向传送 。详见后续 movsb 指令的使用。
- IF :用于中断,仅对可屏蔽中断有效 。当前中断进行时,若碰上其他可屏蔽中断,如果此时 IF=1,则暂停当前中断,转向其他中断;如果 IF=0,则必须执行完当前中断后,才能执行其他中断。若碰上不可屏蔽中断,则无论 IF 为多少,当前中断暂定,转向其他中断。sti 指令设置 IF=1,cli 设置 IF=0。
- TF:TF=1,机器进入单步工作方式,每条机器指令执行后,显示结果及寄存器状态,若TF=0,则机器处在连续工作方式。此标志为调试机器或调试程序发现故障而设置。
- AF:辅助进位标志。在进行算术运算的时候,当两个字节相加减时,如果从第 3 位向第 4 位(从第0位算起)形成了进位或借位,则AF=1,否则AF=0;
mov、push、pop等传送指令不修改标志寄存器的信息。 如何在 debug 中查看标志寄存器,请移步工具使用 。
指令指针寄存器
IP 配合 CS 使用,IP 永远指向下一条指令的偏移地址。任意时刻,CPU 将 CS:IP 指向的内容当作指令执行。
汇编指令用法总结
mov
mov 指令被称为传送指令,用于修改内存或寄存器的值。 注意,mov 指令无法用来设置 CS,IP 的值 。
1 | mov ax,bx |
注意,mov 只能有如下几种形式:
1 | mov 寄存器,立即数 |
不能 mov 内存单元,内存单元 和 mov 段寄存器,立即数 。 需要说明的是,mov 内存单元,立即数 时,必须指明其数据类型是字还是字节:
1 | mov byte ptr[0],12h |
其中,ptr 不可省略。以上规则同样适用于 sub ,add 指令。
jmp
jmp 指令用于指令的跳转,有以下几种用法:
-
jmp 段:偏移:同时修改 CS : IPplaintext1
2
3
4jmp 1000:0012
#5
mov cs,1000h
mov ip,0012h -
jmp reg: 修改 IP 为 reg 寄存器中的值plaintext1
2
3jmp ax
#效果等价于
mov ip,ax -
jmp short 标号/数值:执行段内短转移,对 IP 的修改范围为 -128~127;此方式是利用当前 jmp 指令的下一条指令到标号的偏移量来跳转的,而非利用标号的绝对地址来跳转。实际上jmp short 标号的功能为IP=IP+8位位移;位移在汇编时期算出,用补码表示。plaintext1
2
3
4
5
6
7
8
9
10
11
12
13assume cs:code,ss:stack
stack segment
db 16 dup(0)
stack ends
code segment
mov ax,4c00h
int 21h
start:
mov ax,1
inc ax
jmp short start
code ends
end start -
jmp near 标号/数值/寄存器/内存执行段内近转移;同jmp short 标号类似,利用相对移位进行跳转,但对 IP 的修改范围为 -32768~32767,为 16 位位移。 -
jmp far 内存/数值执行段间转移,又称远转移。与前两者不同,此方式利用的是 CS:IP 绝对地址。 -
jmp word ptr 内存单元段内转移。 -
jmp dword ptr 内存单元段间转移,内存单元中高地址的字存放段地址,低地址的字存放偏移地址。
add与sub
add 与 sub 分别执行加法和减法。所支持格式和 mov 相同。
pop与push
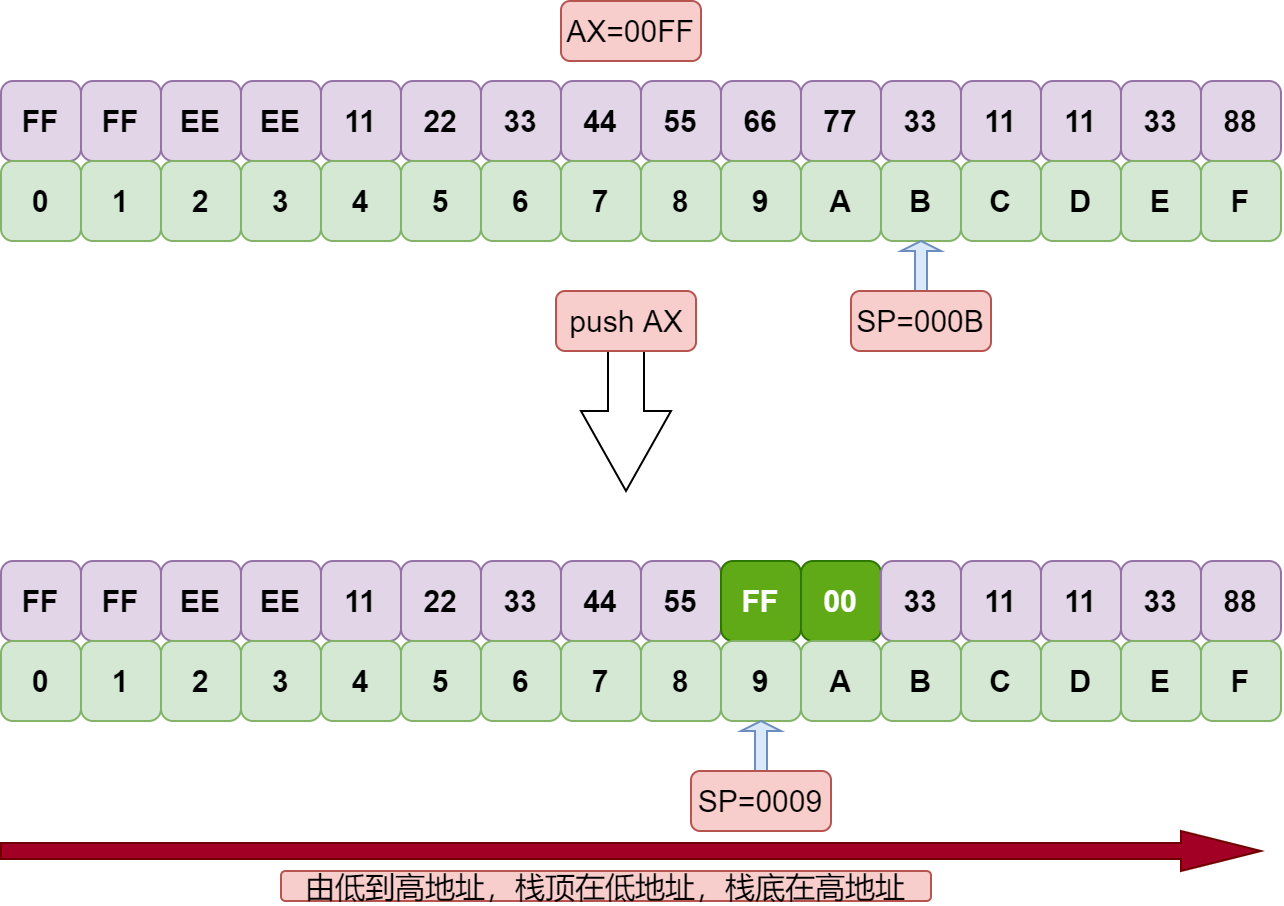
push ax :(1)SP = SP - 2 (2)mov SS:[SP],ax ;
pop ax :(1)mov ax,SS:[SP] (2)SP = SP + 2 ;
注意以下几点:
- 8086 的入栈出栈必须以字为单位进行操作
- 操作数只能为内存或寄存器,不能为立即数,比如:
push 12 - SS:SP 指向栈顶,没有寄存器自动指向栈底(一般用BP手动指向栈底),所以必须自己操心栈顶超界的问题,栈顶 SS:SP 超界会导致严重后果。
- 栈顶的变化范围为 0~FFFF,栈满时如果仍继续压栈,会循环覆盖之前的内容。
pusha与popa
pusha 指令的作用是把通用寄存器压栈。寄存器的入栈顺序依次是:AX,CX,DX,BX,SP,BP,SI,DI。popa 指令按照相反顺序将同样的寄存器弹出堆栈。过程用一个或多个寄存器来返回结果时,不应使用 PUSHA 和 POPA,因为其值会被 POPA 覆盖 。
inc与dec
inc 对寄存器自增 1,dec 对寄存器自减 1:
1 | inc ax |
Loop
loop 的格式为:loop 标号 ;进行 Loop 操作时进行如下两步操作:
-
cx = cx - 1 -
判断 CX 中的值,不为零则跳转到标号继续循环,为零则往下运行。
plaintext1
2
3
4mov cx,5
s:
inc ax
loop s
注意,是先减再判断! 循环指令都是短转移。
and与or
分别是按位与和按位或。
1 | mov al,10010010B |
test
Test 对两个参数 (目标,源) 执行 AND 逻辑操作(&&而非&),并根据结果设置标志寄存器,结果本身不会保存 。
TEST AX,BX 与 AND AX,BX 命令有相同效果,只是 Test 指令不改变 AX 和 BX 的内容,而 AND 指令会把结果保存到 AX 中。
div
div 指令进行无符号除法操作,idiv 执行有符号除法 。如果除数为 8 位,则被除数须为 16 位,放在 AX 中;如果除数为 16 位,则被除数须为 32 位,高位放在 DX 中,低位放在 AX 中。存放商 :如果除数为 8 位,则将商放入 AL,余数放入 AH;如果除数为 16 位,则将商放入 AX,余数放入 DX。有以下两种方式:
1 | div 十六位/八位寄存器 |
计算 100001 ÷ 100(186A1H ÷ 64H)
1 | mov ax,1H |
mul
mul 为无符号数乘法,imul 为有符号数乘法 。相乘的数,要么都是 8 位,要么都是 16 位。
8 位:一个默认放在 AL 中,另一个由操作数给出,放在 8 位寄存器或内存中(不能为立即数);结果默认放在 AX中。
16 位:一个默认放在 AX 中,另一个由操作数给出,放在 16 位寄存器或内存中(不能为立即数);结果高位放在 DX 中,低位放在 AX 中。
1 | #8位 |
jcxz
jcxz 指令为有条件转移指令, 所有的有条件转移指令都为短转移 。当 CX=0 ,则进行跳转。另外,根据
ret与retf
ret :(1)IP = SS:[SP];(2)SP = SP+2;相当于POP IP;
ret imm :(1)IP = SS:[SP];(2)SP = SP+2;(3)SP = SP+imm;相当于 POP IP,SP+=imm;通常用于内平栈。
retf :(1)IP = SS:[SP];(2)SP = SP+2;(3)CS = SS:[SP];(4)SP = SP+2;
call
call 标号 :(1)SP = SP-2;(2)SS:[SP] = IP;(3)jmp near 标号;实现段内转移
call far 标号 :(1)SP = SP-2;(2)SS:[SP] = CS;(3)SP = SP-2;(4)SS:[SP] = IP;(5)jmp far 标号;实现段间转移
call 16位reg :(1)SP = SP-2;(2)SS:[SP] = IP;(3)IP = reg;实现段内转移
call word ptr 内存单元 :(1)SP = SP-2;(2)SS:[SP] = IP;(3)IP = 内存单元中的值;
call dword ptr 内存单元 :(1)SP = SP-2;(2)SS:[SP] = CS;(3)SP = SP-2;(4)SS:[SP] = IP;(5)CS = 内存中高地址的字;(6)IP = 内存中低地址的字
adc
带进位加法指令。指令格式:
1 | adc operand1,operand2 |
功能:oprand1 = operand1 + operand2 + CF
这个指令的作用看上去比较鸡肋,但实际上对于大数运算很有帮助。首先我们知道这样一个常识:
加法分两步执行:1)低位相加;2)高位相加再加上低位相加的进位值。 例如下面的指令与 add ax,bx 有完全相同的结果:
1 | add al,bl |
16 位 CPU 如何计算 32 位数的运算?比如 11FF89FF33420010 + 12983476FFAAB444 :
1 | mov ax,11FF89FF #ax存第一个加数的高位 |
这个指令是字长还只有8位时发明的,当时八位寄存器经常难以承担运算任务,所以 adc 必不可少。现在已经进入 32/64 位时代,除了科学计算,一般都够用了。
sbb
带位减法指令,原理和 adc 相同,不再解释。
cmp
cmp 指令用来比较大小,格式如下:
1 | cmp operand1,operand2 |
1 | ##对于无符号数,通过zf,cf来判断: |
要理解这种工作机制背后的思想。
根据比较结果进行跳转
无符号比较:
| 指令 | 含义 | 检测标志位 | 助记 |
|---|---|---|---|
| je | 等于则转移 | zf=1 | jump if equal |
| jne | 不等于则转移 | zf=0 | jump if not equal |
| jb | 小于则转移 | cf=1 | jump if blow |
| jnb | 不小于则转移 | cf=0 | jump if not blow |
| ja | 大于则转移 | cf=0且zf=0 | jump if above |
| jna | 不大于则转移 | cf=1或zf=1 | jump if not above |
1 | cmp ax,bx |
其他根据比较结果进行跳转的指令参考跳转指令汇总
movsx
常用的有 movsb,movsw,movsd 。
将源字符串高效地传送到目的地,movsb 相当于以下几步操作:
1)ES:[DI]=DS:[SI]
2)如果 DF=0,则 SI++,DI++ ;如果 DF=1,则 SI--,DI-- ;
movsw 类似,只是每次移动两个字节:如果 DF=0,则 SI+=2,DI+=2 ;如果 DF=1,则 SI-=2,DI-=2 ;
movsd 则每次移动四个字节。
cld 指令将 DF 置为 0,std 将其置为 1。
movsb 与 movsw 通常和 rep 指令搭配使用,效果如下:
1 | rep movsb |
可见,rep 的功能就是根据 CX 中的值重复循环后面的指令。程序演示如下:
1 | assume cs:code,ds:data |
pushf与popf
pushf 的功能是标志寄存器的值压栈,popf 从栈中弹出数据,送入标志寄存器中。该指令与中断有关,详见 中断
iret
功能如下:
1 | pop IP |
该指令用于中断程序的返回。
shl与shr
shl 逻辑左移,shr 逻辑右移:
1 | shl ax,1 |
当移动位数大于 1 时,必须将移动位数放入 CL;以上指令将最后移出的一位写入 CF 中 。
seg
取得某一标号的段地址。
程序返回
使用如下命令进行程序返回:
1 | mov ax,4c00h |
此指令相当于 main() 函数中的 return 0 语句。
伪指令总结
以下伪指令为 masm 的格式 ,nasm 与 masm 格式的区别见文末。
伪指令由汇编器识别并进行相关汇编工作,没有对应的机器码。 可执行文件由描述信息和程序组成,程序来源于源程序( .asm文件 )中定义的指令和数据;描述信息则来自于 .asm 文件中的伪指令,比如程序入口地址就由伪指令 end 提供 。 注意,伪指令的类型随汇编器的种类不同而不同,比如 masm 和 nasm 就不一样,以下伪指令为 masm 的格式。
常见伪指令如下:
-
segment和ends是成对出现的伪指令,用来定义一个段;前者说明段的开始,后者说明段的结束。 -
end(注意不是ends)用来标记整个汇编程序的结束,其后可以跟标号,指明程序的入口 :plaintext1
2
3
4
5
6
7
8
9
10
11
12assume cs:code,ds:data
data segment
dw 0FFFF,0EEEE
data ends
code segment
mov ax,4c00h
int 21h
start:
mov ax,ds:[0]
ret
code ends
end startend start指明程序入口为第八行的start。 -
assume用来假设某一段寄存器和程序中某个用segment和ends定义的段相关联。 -
+、-号等,只能用立即数,在汇编时期就会算出结果。如:mov ax,90-4 -
dw,db,dd,dq用来声明段内存空间,即“define word”,“define byte”,“define double word”,“define quadword”(8 字节);plaintext1
2
3
4
5
6
7stack1 segment
dw 0FFFF,0FFFF,0FFFF
stack1 ends
stack2 segment
db 11,22,33,44
stack2 ends -
dup指令用来声明装载重复数据的内存空间,比如上面代码中第 2 行可以写作:plaintext1
2
3
4
5
6
7
8
9
10
11
12
13stack1 segment
dw 3 dup(0FFFF)
stack1 ends
7. `offset` 用来取得标号到段首的偏移量,如下:
```assembly
codesg segment
mov ax,4c00h
int 21h
start:
mov bx,offset start
code endsbx 中即取得 start 标号地址(实际就是第五行
mov的地址)到 codesg (第二行mov的地址)的偏移量。可以用 offset 求某段的长度:plaintext1
2
3
4
5
6
7
8
9
10
11codesg segment
mov ax,4c00h
int 21h
start:
mov bx,45h
mov cx,8
push cx
push bx
mov dx,offset s - offset start
s: nop
code ends -
汇编中除了汇编指令和伪指令外,还有标号,例如
codesg segment中的codesg。标号是地址的助记符,标号本身即代表地址。如下代码第 9 行。注意,:只能在代码段使用 。plaintext1
2
3
4
5
6
7
8
9
10
11
12assume cs:code,ds:data
data segment
dw 0FFFF,0EEEE
data ends
code segment
mov ax,4c00h
int 21h
start:
mov ax,data
ret
code ends
end start -
数据标号:带有单元长度的标号:
plaintext1
2
3
4
5
6
7
8
9
10
11
12
13
14
15assume cs:code,ds:data
data segment
a dw 0FFFFh,0EEEEh
b dw 0
data ends
code segment
mov ax,4c00h
int 21h
start:
mov ax,data
mov ds,ax
inc b[0] ##无需word ptr
ret
code ends
end start
汇编规则总结
-
注释以分号
;开头。 -
指令的两个操作对象的位数必须一致,以下是不正确的用法:
plaintext1
2mov ax,bl
add bh,1000 -
AH 与 AL 是两个独立的寄存器,不要错误地认为
add al,93H指令产生的进位会储存在 AH 中。 -
数据在内存 21F60 单元中,专业说法应该为:2000:1F60 单元中。
-
8086 CPU 不支持将数据直接送入段寄存器,必须通过寄存器将数据送入段寄存器,也不允许直接在段寄存器上做运算 ;
plaintext1
2
3
4
5#错误
mov ss,1100
#正确
mov ax,1100
mov ss,ax -
mov 指令中给出 16 位寄存器,就进行 16 位数据传送;若给出 8 位寄存器,则进行 8 位数据传送:
plaintext1
2mov ax,[0]
mov al,[0]对于没有寄存器参与的内存单元操作指令中,必须要用
word ptr和byte ptr指明操作长度。plaintext1
2mov word ptr [0],0fffh
inc byte [0] -
注意,在编写汇编代码时,如果数字后没H或没有前缀0x,则视为十进制数,汇编过程中自动再转为十六进制。
-
为了使程序更加清晰合理,一般将数据、代码、栈放在不同的段中。由于寄存器最大为 16 位,所以一个段的容量最大也为 64KB
-
8086 CPU 的转移指令分为以下几类:1)无条件转移指令(jmp);2)条件转移指令(jcxz);3)循环指令(loop);4)call 与 ret;5)中断
-
如前所述,
jmp short 标号,jmp near 标号,jcxz 标号,loop 标号都是根据相对位移来进行转移的。这样做的好处是方便了程序的整体移动。比如我把这段程序中的某段代码移植到其他程序中,就只需要更改段寄存器。 -
设置 SS 后必须紧接着设置 SP!!!原因见内中断。
程序设计规范
后续补充、、、先列个目录:
- 10.10 参数和结果的传递
- 10.11批量数据的传递
- 10.12寄存器冲突
- 在子程序内部保存用到的寄存器。
代码实验
一. 往屏幕中间输出 hello(masm下):
1 | assume cs:code,ds:data |
彩色模式详见王爽《汇编语言第四版》第188页。
工具使用
汇编工具下载链接:汇编工具
提取码:gzwb
工具的安装和配置
Debug 是 Dos 和 Windows 都提供的 实模式 (8086方式) 程序的调试工具,它可以查看 CPU 中各种寄存器的值和内存的使用情况,并能够在机器码级跟踪程序的运行。参见 DosBox安装 。DosBox 安装好后直接将 LINK.exe 、masm.exe 和 Debug.exe 放入 DosBox 的根目录中。
Debug指令
-
R:查看或改变寄存器的值;
shell1
2
3
4
5查看
D:\>debug
-r
AX=0000 BX=0000 CX=0000 DX=0000 SP=00FD BP=0000 SI=0000
DI=0000 DS=073F ES=073F SS=073F CS=073F IP=0100 NU UP EI PL NZ NA PO NC 073F:0100 0000ADD[BX+SI],ALDS:0000=CDshell1
2
3
4
5
6
7
8
9修改
D:\>debug
-r AX
AX 0000
:FFFF
-r
AX=FFFF BX=0000 CX=0000 DX=0000 SP=00FD BP=0000 SI=0000
DI=0000 DS=073F ES=073F SS=073F CS=073F IP=0100 NU UP EI PL NZ NA PO NC
073F:0100 0000 ADD[BX+SI],ALDS:0000=CD #下一次要执行的指令第二行最后八对字母是标志寄存器的状态,含义如下:
标志 1 0 OF OV NV SF NG PL ZF ZR NZ PF PE PO DF DN UP AF AC NA IF EI DI -
D:查看内存中的值;
shell1
2
3
4D:\>debug
-d 1000:0
1000:0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
...... -
E:修改内存中的值;
shell1
2
3
4
5
6D:\>debug
-e 1000:0
1000:0000 00.FF 00.11 #按空格继续修改,回车终止
-d 1000:0
1000:0 FF 11 00 00 00 00 00 00 00 00 00 00 00 00 00 00
......... -
U:将内存中的指令翻译成汇编指令。
-
T:执行一条机器指令。
-
A:以汇编指令的形式向内存写入机器指令;
shell1
2
3
4
5
6-a
073F:0100 MOV AX,FF
073F:0103 ADD BX,EE
-u 073F:0100
073F:0100 BBFF00 MOV AX,FF
073F:Θ103 81C3EE00 ADD BX,ΕΕ -
P:执行指令,不过遇到子程序代码时,直接完成子程序的执行,类似于 VS 调试时使用 F10,而 T 相当于 F11;遇到循环时,直接执行到 CX=0;
-
G: 该命令后面可以跟地址和断点,运行到内存指定位置的代码后暂停,如果不加参数默认是从当前IP运行到程序结束。
注意,在debug中所有数据被视为十六进制,不能在数据后再加H;而在编写汇编代码时,如果数字后没H,则视为十进制数,汇编过程中再转为十六进制。
生成可执行文件
编写 test.asm 后保存,在 DosBox 中输入 masm ,然后输入 test.asm ,连续回车;接着输入 link test.obj ,连续回车;最后 debug test.exe 即可。
Dos下exe文件加载过程
.PNG)
程序加载后,DS 指向 PSP 的起点,CS 指向程序的入口。PSP 的作用和程序加载器差不多,关于程序加载器,见另一篇文章:程序加载器 。
补充:nasm 的使用
后续学习操作系统的过程中我们都会在 Linux 下采用 nasm 。原因 nasm 可以直接生成纯二进制文件,不夹杂其他的文件信息,而 masm 则会自动生成文件信息(利用 assume, start, end 等伪指令生成信息),不利于我们探究其中的细节。
命令行语法
1)将文件进行汇编
1 | #将myfile.s生成bin文件,生成的文件名为myfile |
- 汇编文件后缀在 Linux 下以
.s为主,在 Windows 下以.asm为主。.bin文件是纯二进制文件,其中只包含汇编指令,可以直接给 CPU 使用。而 ELF 或 PE 文件是二进制可执行文件,除了指令外还包含很多文件信息,用来给程序加载器使用。
2)生成列表文件
1 | nasm -f coff myfile.s -l myfile.lst |
列表文件很方便我们对照阅读汇编代码和其对应的二进制代码:

3)预包含文件
1 | nasm myfile.s -p myinc.inc |
跟在源文件开头写上 %include "myinc.inc" 是等效的。这种包含头文件的方式将在后面我们写加载器时带来很大的方便。
伪指令
1)段定义
1 | section .data [vstart] [align] |
masm 的段定义格式为 data segment 。关键字 vstart 很不好理解,关于 vstart 和 align 的详细讨论参见:程序加载器 。
.data,.code,.bss,.text是标准的段名。
.data:用来存放程序中已初始化的全局变量的一块内存区域;
.bss:用来存放程序中未初始化的全局变量的一块内存区域;
.code\.text:用来存放程序代码
2)$ 和 $$
此二者常用来计算偏移量或文件大小。$ 表示当前行的汇编地址, $$ 表示本 section 的起始汇编地址, 它们两都受 vstart 影响。举个例子:
1 | section .data vstart=0x100 |
以上 $ 的值为 0x100+5=0x105 ,$$ 的值为 0x100 。
3)声明重复内存单元
masm 中使用如下格式声明重复的零内存:
1 | dw 100 dup(0) |
nasm 则如下:
1 | times 100 db 0 |
4)段前缀
在 masm 下可以这样使用:
1 | mov ax,ds:[1000] |
在 nasm 下则必须这样使用:
1 | mov ax,[ds:1000] |
5)指明内存操作数的大小
在 masm 中必须使用 size ptr :
1 | push byte ptr [1000] |
在 nasm 中不需要加 ptr 。
1 | push byte [1000] |
6)equ 定义宏
equ 用来为标识符定义一个整型常量,它的作用类似 C 语言中的宏。equ 不占任何内存,编译时会自动替换成相应值。
7)定义数据
dw,db,dd,dq用来声明初始化内存空间(用于 .data 段),即“define word”,“define byte”,“define double word”,“define quadword”(8 字节);resw,resb,resd,resq用来声明非初始化内存空间(用于 .bss 段)。
