实现系统打印函数/除法溢出
概述
-
实现
put_char()函数,这是最基础的系统级打印函数,其他打印函数都基于此函数 。 -
实现
put_str()函数,该函数以put_char()为基础,极大地方便了字符串的打印。 -
实现
put_int()函数,该函数以put_str()为基础,支持有符号 32 位整型的打印,同时支持十进制与十六进制格式打印 。 -
后续文章将利用以上函数实现
printf()可变参打印函数。注意,前三者是系统级打印函数,也就是所谓的系统调用,和普通的库函数(如printf)要区分开。
函数原型如下 :
1 | enum radix{HEX=16,DEC=10}; |
实现打印函数之前,我们还需要了解一些显存的知识。毕竟是系统调用,多多少少都会直接操作硬件,话不多说,开干。
显存的端口操作
之前咋们都是通过直接操控 0xb8000 的显存区域来实现屏幕输出,为啥现在要使用端口啦?简单来说,是为了方便。我们之前一直使用如下类似的方式进行打印:
1 | mov ax,0xb8000 ;现在是在保护模式下,所以是0xb8000而非0xb800 |
这种方式的麻烦之处在于:
- 一行代码只能打印一个字符。显然,我们不可能用这个方法打印一整屏的内容。
- 我们必须手动指定打印位置。屏幕内容少时还能接受,一旦屏幕内容较多,打印时稍有不慎就会将之前的内容覆盖。
而通过操作显存端口来获得光标位置后,我们就可以放心地将字符定位任务交给光标啦。
操作端口的直接原因就是为了获取光标位置。 需要注意的是,在实模式下可以通过 BIOS 中断来获取光标位置,进入保护模式后就不能再使用 BIOS 中断了,所以必须手动操作端口。
显卡一般有 CGA、EGA、VGA 三种显示标准,功能复杂,这使得显卡具备相当多的寄存器(端口)。我们知道,计算机系统为这些端口统一编址,每个端口占用一个地址(Intel 系统的寄存器地址范围为 0~65535,注意,这个地址可不是内存地址 )。如果为显卡的每个端口都分配一个系统端口
地址,这就十分浪费硬件资源了,毕竟显卡如果这么干,那就意味着其他硬件也能这么干,那端口地址不一会就会分配光啦。所以,制造商根据功能的不同将显卡寄存器分为不同的组(并排列成数组),每个组中有两个特殊的寄存器:1)Address Register ;2)Data Register 。Address Register 作为数组的索引,通过该寄存器来指定要访问的寄存器;Data Register 则用来输入输出,相当于所有寄存器的读写窗口 。
CGA :彩色图形适配器,提供两种标准文字显示模式:40×25×16 色和 80×25×16 色;以及两种常用的图形显示模式:320×200×4 色和 640×200×2 色;
EGA :增强图形适配器,在显示性能方面(颜色和分辨率)介于 CGA 和 VGA 之间;
VGA :视频图形阵列,具有分辨率高、显示速率快、颜色丰富等优点,在彩色显示器领域得到了广泛的应用,VGA最早指的是显示器 640×480 这种显示模式。
.PNG)
以上只对显卡寄存器做了个简单的讲解,因为我们待会也只需要通过端口获取光标而已,就不再做过多阐述,避免劝退。
1 | ;获取光标 |
注意,读写 8 位端口时,只能用 al 中转;读写 16 位端口时,只能用 ax 中转。
print_char
这三个系统调用我们都使用汇编来写,实际上,这里使用汇编比 C 语言更简单。不用害怕,就 put_char 稍长一点,但其逻辑十分简单。
1 | ;------------------------ put_char ----------------------------- |
这里的代码笔者直接扣的《操作系统:真相还原》(略作修改),代码注释已经非常清晰,下面对部分内容做说明:
- 第 7,8 行:为了防止将来因为 GS=0 导致 CPU 抛出异常(选择子不能为0,还记得吗),这和特权级有关,后面文章会剖析。
- 第 28,29 行:这里直接使用 esp 来定位参数,并不规范。一般我们会在函数开头
push ebp,mov ebp,esp,然后使用 ebp 来定位参数。 - 第 77,81 行,
cld与rep movsd详见汇编入门 。
以上就是 put_char 的内容,代码多,但逻辑简单。
put_str
put_str 以 put_char 为基础,代码相对简单。
1 | ;-------------------------------------------- |
put_int
put_str 和 put_char 笔者直接使用的《操作系统:真相还原》中的代码,而 put_int 为笔者原创,添加了有符号数打印与十六进制格式打印,代码质量不敢作保证(本人菜比),如有错误,请读者指出。下面内容较多,请读者打起精神继续阅读,哈哈。
1 | ;====================put_int=========================================== |
代码注释很详细,笔者只解释以下几个地方:
-
如何在 buffer 中定位字符?流程如下:
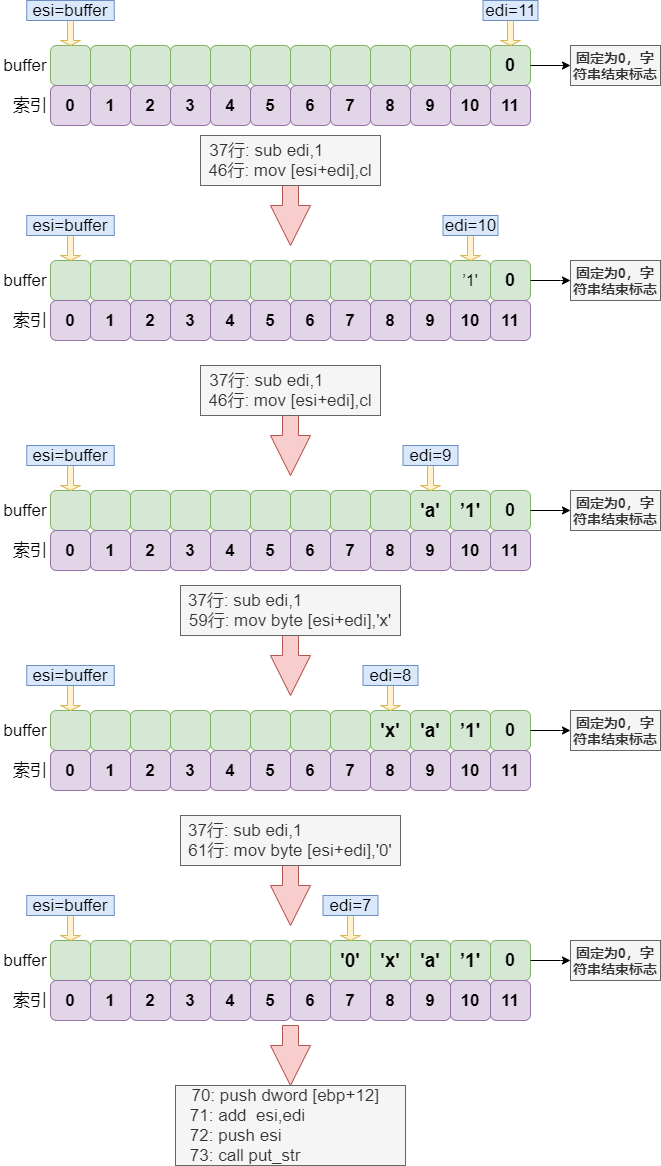
-
第 10,11 行使用 ebp 来定位参数。笔者在这吃过大亏,曾想当然地省略了第 10 行,结果就是排了一天的错。在函数内使用过的寄存器一定要提前保存!
-
为什么第 39 行除法不直接使用
div指令,而使用 divdw 函数呢?这是因为 div 可能发生溢出,即 除法溢出 ,这将引发 CPU 异常。div 指令功能为:如果除数为 16 位,则被除数须为 32 位,高位放在 DX 中,低位放在 AX 中;将商放入 AX,余数放入 DX。而当被除数为 100000,除数为 1 时,商就无法完全存入 AX,从而发生溢出。为了避免这一问题,我们就用 divdw 函数来进行除法操作。divdw 原理剖析见文末。 -
注意,字符串末尾必须为 0 !在 C 语言中,字符串 “abcd” 会在编译时由编译器在其末尾加 0,但是在汇编中,0 必须要我们自己加!
\n也是如此,在汇编中,以下数据:1
data db"wow!\n"
最后的
\n会被解析为\和n!这是因为高级语言中的\n是在编译阶段被识别并处理为 ASCII 码0x8,这个转换是编译器的功劳。而我们自己手写汇编时,可不会还经过编译器处理。 -
有人可能不明白为什么三个参数在栈中的位置分别是 [ebp+18],[ebp+12],[ebp+16],这意味着这三个参数的大小都是 4 字节。问题在于,我们的函数原型是
put_int(int, unsigned char, enum radix);,第二个参数是 char 呀,不应该只压入 1 个字节吗?是这样的,C 语言不管函数参数类型是 char 还是 short 或者 int,压参时每个参数都会压入 4 字节 ,关于这点的讨论请参见C和汇编混合编程 。
关于上面的除法溢出,可以利用后面将学习的中断描述符表(IDT)来检验,如下:
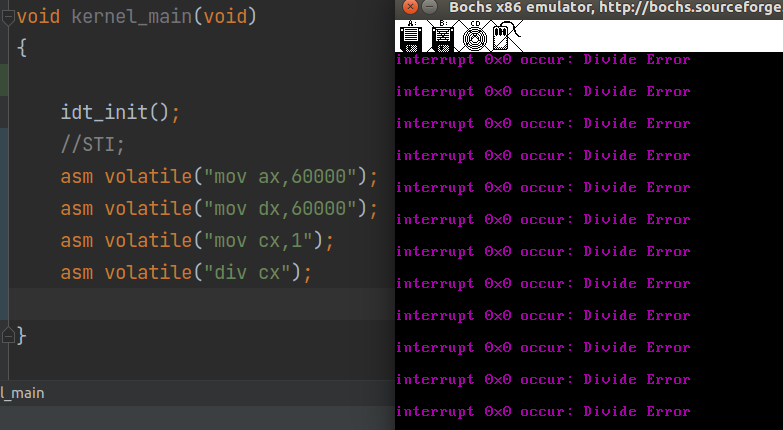
显然,除法溢出引发 CPU 的 0 号异常。
最后,来看看效果:
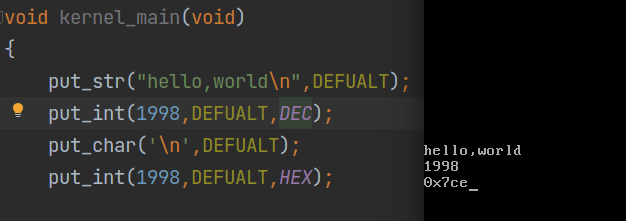
大功告成!
另外,负十六进制数一般是由补码形式来显示的,这里转换就比较复杂,所以上面的 put_int 没考虑这一点,直接在十六进制数前加负号。
补更:后续学习中发现有符号整型不够用(比如显示地址,大于 2GB 就为负了),因此还需要一个无符号整型打印函数 put_uint,该函数的实现也只是在 put_int 上稍作修改,具体请参考
memory分支。
divdw原理浅析
为避免除法溢出,我们将一次除法分解成两次除法,核心公式为:
其中,
我们一步一步来分析:
- 首先我们要知道, ,这个大家一定都清楚。正确的等式(注意是等式,而非赋值)应该为: ,即得 。
- 接下来的问题是, 如何得到 ?这个简单:
得证。
由此,我们便将 X/n 分解成了 H/n 和 L/n ,这无论如何也不可能发生溢出。




