
线程-基础-加载线程
嚯,跨过千山万水,咋们终于要实现线程啦!这是既内存管理后,笔者最期待的部分。正式开干前,先让我们了解一下本节的学习框架。
概览
- 并发和并行、同步与异步
这是常见而又容易混淆的几种关于任务执行的概念,它们与线程、进程息息相关。 - 任务、进程、线程
任务是 CPU 的最小调度单元;任务既可以是线程,也可以是进程;线程是在进程基础上进行的第二次并发 。 - PCB
进程/线程的身份证,用于存放进程/线程的管理和控制信息。 - 线程的内核态与用户态实现
粗略了解这两种方式的优缺点以及现代操作系统对线程的实现模型。 - 线程实现
初步实现线程,这是下节实现任务调度的基础。
并发与并行、同步与异步
并发和并行
并发又称“伪并行” ,并发的实质是一个物理 CPU 在若干道程序之间来回切换,每一刻都只有一个任务在 CPU 上执行 ,但因为切换任务的速度相当快,所以看上去是多个任务同时执行。
需要注意的是,伪并行降低的是任务的平均响应时间,也就是说,并发让执行时间短的任务可以不必等待那些执行时间长的任务完全结束后再被调度,因此任务的响应速度快了许多;然而,所有任务的总执行时间实际上不减反增,这是因为任务切换也需要时间 。但显然,如果能让后面的紧急任务能够及时完成,这点时间成本是微不足道的。
并行则是真正意义上的多个任务同时执行,这必须建立在多核处理器的基础上,每个任务在不同的核上进行 。
另外,还有一个常见的名字是“串行”,并行和串行都指任务的执行方式。串行是指存在多个任务时,各个任务按顺序执行,完成一个之后才能进行下一个 ,并发的工作方式即为串行。
同步和异步
同步和异步,以及阻塞和非阻塞,这两组概览看上去简单,实际上有很多细节需要区分。笔者尚未有讲解该知识点的能力,详细请参考同步和异步、阻塞与非阻塞 。
任务、进程、线程
任务是一个相对而言比较抽象的概念,它是软件发起的某一个活动,其既可以是线程,也可以是进程。任务是独立的执行流,每个任务都具备自己的一套资源(栈、寄存器映像等),这些资源是保证该任务能够被 CPU 单独执行的关键 !什么叫做被 CPU 单独执行呢?举个例子:在 A 任务中调用了 func() 函数,这个 func() 函数是随 A 任务一块被带上处理器的,实际的调度单元是 A 任务而非该函数,换句话说,这个函数是在更大的执行流(A任务)中被“夹杂着、捎带着”执行的,甚至有可能没有等到执行该函数,任务 A 就被换下了 CPU 。在这个例子中,任务 A 为调度单元,即被 CPU 单独执行。如果我们想让 func() 函数成为单独的执行流,就必须为它分配上下文环境,使其成为任务。
线程是任务调度的基本单位 ,是独立的执行流,而进程则是多个线程的集合。它们的联系与区别如下:
-
进程是对运行时程序的封装,是 系统进行资源调度和分配的的基本单位,实现了操作系统层面上的并发 ;线程是进程的子任务,是 CPU 任务调度和分派的基本单位,是在进程基础上实现的第二次并发 。
-
一个进程可以有多个线程,同一进程的所有线程共享该进程的资源 ,如地址空间、代码段(代码和常量),数据段(全局变量和静态变量),扩展段(堆存储);但是每个线程拥有自己的栈段,用来存放所有局部变量和临时变量 。
需要强调的是,每个进程都有自己的 4GB 虚拟空间,同一进程内的线程共享该虚拟空间。
-
进程可分为单线程进程与多线程进程,在我们平时写的程序中,如果没有显式创建线程,那么该程序就是单线程进程。线程不能独立于进程而存在。
-
进程=资源+线程 。
Window 对线程和进程的实现如同教科书一般标准,不仅在概念上对线程和进程有明确的区分,在 API 上也是如此:使用 CreateProgress 和 CreateThread 来分别创建进程和线程。而在 Linux 下就不存在明显的线程概念,其将所有的执行实体都称为任务(task),并由 task_struct 结构体负责管理任务。这个task_struct 数据结构囊括了进程管理生命周期中的各种信息 。
刚才我们提到,在某个任务中调用 func() 函数,则此函数是随该任务一起被放上 CPU 执行的,并非单独的执行流。那么有没有方法能够使某个函数成为单独的执行流呢?有,就是通过线程。在高级语言中,线程是运行函数的一种方式 ,与普通函数的执行方式不同,线程机制可以为函数创造它所依赖的上下文环境,使函数代码具有独立性,进而能被 CPU 单独调度。下面是 Linux 下 C 语言创建线程的方式:
1 |
|
暂不深究 pthread_create() 函数,有兴趣的同学请自行研究。
有了进程为什么还要引入线程?
- 每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,线程之间切换的开销小。所以线程的创建、销毁、调度性能远远优于进程。
- 同一进程内的线程共享资源,因此它们之间相互通信无须调用内核,比进程间通信更方便。
- 进程采用多个线程(执行流)和其他进程抢占处理器资源,从而节省单个进程的总时间。
- 避免某些阻塞使整个进程都被挂起。
那么,在同一个进程下,哪些资源被线程共享,哪些又是线程私享的呢?一般的评判标准是:如果资源独享会导致线程运行错误,则该资源由线程共享。下表给出一般情况下的共享与独享资源划分:
线程共享资源 线程独享资源 地址空间 栈 全局变量 寄存器 打开的文件 状态字 子进程 程序计数器 堆 … …
PCB
PCB(Process Control Block,程序控制块),用于唯一地标识一个进程和记录进程的相关信息。PCB 的具体格式并不固定,这取决于操作系统厂商 。PCB 的一些基本信息如下:
| 内核栈 | 内核栈指针 | 优先级 | PID | 时间片 | 页目录表指针 | 进程状态 | … |
|---|
现代操作系统的 PCB 已经相当复杂,加之笔者也没有深入了解,因此本文不再对其展开,只说我们后面将要用到的东西以及重点内容:
-
我们的操作系统较小,PCB 只会占到一页内存 。在 PCB 的顶部是内核栈,内核栈分为中断栈与任务栈;PCB 底端则是 PCB 的相关信息,如栈指针、PID、时间片等 。这点在 内存管理基础中说过,忘记的同学还请回头看看。
既然是内核栈,说明此栈是在 ring0 下使用的栈,而非 ring3 下的用户栈 。就因为栈在 PCB 中,所以 PCB 才会占一页的大小。为什么要为每个线程都分配一个内核栈呢?大概有以下原因:
- 线程切换就是通过栈切换来实现的(下节内容),如果所有线程共享一个栈,就没法完成任务调度啦。
- 将线程相关的所有资源的集中在一起,方便管理。比如线程执行后需要销毁,由于 PCB 中存放着该任务的所有资源,所以直接回收该 PCB 就行了,无需其他多余动作(当然,堆管理另说,这由程序员自己负责 free,否则内存泄漏)。
-
不是说同一个进程下的线程共享虚拟空间吗,那为什么 PCB 中还会有页目录表指针呢?是这样的,Linux 中不论线程还是进程,都统一由 task_struct 结构体管理,对于线程,页目录表指针被初始化为 NULL;对于进程,页目录表指针指向该进程的页目录表起始地址 。这是线程和进程的最大区别。另外,在进程创建之初,会重新加载 CR2 寄存器(该寄存器中存放的是页目录表的物理地址),这将在后续实现用户进程时提到。
-
优先级并不是说谁先执行,而是指定每次任务执行时所经历的中断次数。初始状态下,时间片等于优先级。之前说过,任务切换是由时钟中断驱动的,也就是说任务调度是在时钟中断处理函数中进行的 。当 A 任务刚被调度上 CPU 时,时间片被初始化为优先级,之后每发生一次中断,时间片就自减 1,当时间片等于 0 时,该任务被换下 CPU 。因此,优先级越大,占用 CPU 的时间就越长 。
-
严格来说,内核栈指针并不是用来指向内核栈的(内核栈永远位于 PCB 顶端),它是用来指向内核寄存器现场的 。读者看完这句话一定是一头雾水,不急,该指针是任务切换的核心,下节我们会重点剖析该指针的作用,敬请期待。
-
PID就是各进程的身份标识 ,程序一运行系统就会自动分配给进程一个独一无二的 PID 。PID 只是暂时唯一的,在进程中止后,这个号码就会被回收,并可能被分配给另一个新进程 。PID 将在后续添加,目前暂时不用。
-
一般来说,按进程在执行过程中的不同情况至少要定义三种不同的进程状态:运行态(running)、就绪态(ready)、阻塞态(blocked) 。在我们的操作系统中,定义了六态:运行态(running)、就绪态(ready)、阻塞态(blocked)、等待态(waiting)、挂起态(hanging)、终止态(dead)。这几态的作用将在后续实现一一体现。
虽然叫做“进程状态”,但这可不意味着只有进程才能使用这个信息,线程同样能使用。
线程的内核态与用户态实现
由于线程依附于进程而存在,所以其储存方案无需额外设计,而是直接使用进程的储存方案(这就是 Linux 中进程和线程都是用 task_struct 结构体作为任务信息存储结构的原因)。虽然进程与线程采用了相同的储存方案,但两者的调度方式却有所不同。线程产生于进程,理所当然的,其调度就可以由进程负责(用户态);另一方面,线程调度也可以交给操作系统来管理(内核态)。
进程调度只能由操作系统负责,并不存在用户态一说。
内核态实现
优点:
-
并发性高。采用与进程类似的调度方式,从而使线程实现进程级并发。
什么是进程级并发?由于操作系统直接控制进程,所以当某个进程被阻塞时,操作系统能够立刻检测到这个情况并将其他进程调度上 CPU 。对于内核态实现的线程而言,当某个线程被阻塞,操作系统也可以立即反应过来,并将其他线程调度上 CPU。
-
简化用户编程。线程的复杂性由操作系统承担,程序员无需关心线程的调度。
-
提升了进程的速度。当进程内的线程较多时,该进程占据的 CPU 资源就更多,执行时间就越短。
缺点:
- 效率较低。每次调度都需要进入内核态,多了些现场保护的栈操作,因此减小了效率。
- 占用稀缺的内核资源。线程的数量远多于进程数,因此随着线程的数量增加,内核空间将迅速被耗尽。
- 内核态的实现需要修改操作系统。这在提出线程的初期是很难办到的,操作系统厂商可不会轻易将一个未被证明的新概念加入到操作系统中。因此,最初只能由用户自己管理线程。
用户态实现
优点:
- 灵活性高。操作系统不知道线程的存在,其仅对用户可见,因此在任何操作系统上都能够实现此方式。
- 切换效率高。无需进入内核态,减少了栈操作。
缺点:
- 编程变得复杂。不同于由时钟中断驱动的内核态任务调度,程序员必须时刻考虑什么时候主动让出 CPU ,将控制权交给其他线程。实际上,一旦线程多起来,人为管理将是巨大麻烦。
- 无法实现进程级并发。用户态实现下,当进程中的某个线程被阻塞,这将使整个进程都被阻塞!这是致命的缺点。
现代操作系统的线程实现模型
现代操作系统对以上两种实现取其精华、剔其糟粕,将二者有机结合:用户态负责进程内部在非阻塞时的切换;内核态负责线程阻塞时的切换 。同时,每个内核态线程可以负责多个用户态线程,比如,某进程有 5 个线程,操作系统将这 5 个线程划分为两组,一组 2 个,另一组 3 个,每组使用一个内核线程,如下图:
.PNG) 当某个线程阻塞时,同组的线程皆被阻塞,当另一组仍可继续执行。如此一来,该模型就缓解了以上两种方式的缺点:
当某个线程阻塞时,同组的线程皆被阻塞,当另一组仍可继续执行。如此一来,该模型就缓解了以上两种方式的缺点:
- 不必为每个线程都创建对应的内核线程,减小了内核资源的压力。
- 不会因为一个线程的阻塞而使整个进程被挂起。
- 用户态线程的切换无需经过内核,提高了效率。
注意,为了简单,本操作系统仅使用内核态实现。
实现线程
本节是对线程的简单实现,主要让大家理解操作系统是如何 通过栈切换来完成线程切换的 。下面先看 thread.h:
1 | //thread.h |
-
第 4 行 task_status 枚举定义了前文提到的六态:运行态(running)、就绪态(ready)、阻塞态(blocked)、等待态(waiting)、挂起态(hanging)、终止态(dead) 。
-
第 14 行定义了中断栈。注意,结构体中靠前的成员位于内存低地址,靠后的成员位于高地址,所以可发现,结构体成员的声明顺序和
interrupt.s中的压栈顺序是对应的: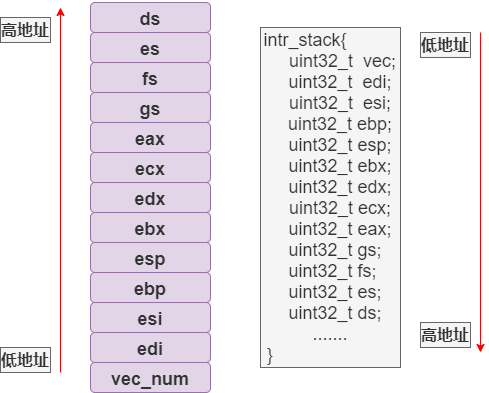
必须要说明的是,虽然这两者是一一对应的关系,但我们并不会通过intr_stack结构体来取得栈中寄存器的值 !原因有两点:1)没必要取得这些寄存器的值,它们仅用来保护现场。为了安全,也不建议获取它们的值;
2)无法保证一定是一一对应的关系。比如,最下方的 SS 和 ESP,此二者仅在发生特权级转移时才会压入,所以是否发生特权级转移将直接影响其对应关系。因此,无法通过该结构体获取栈中的值。那为什么还要声明这个结构体呢?没有其他原因,只是为了得到该中断栈的大小 ,以便后续跳过该栈。 -
第 39 行是线程栈,该栈有两个作用:
1)保存任务调度的现场,即 ebp、ebx、edi、esi 这四个寄存器。为什么只保存这四个寄存器?这涉及到 ABI,见C与汇编混合编程。
2)指定线程中要运行的函数及其参数。即最后四个成员。下面重点说说这几个成员:-
eip:创建线程时,我们会将 eip 指向 kernel_thread() 函数,通过 kernel_thread 来调用想运行的函数:
c1
2
3static void kernel_thread(thread_func* function, void* func_arg){
function(func_arg);
} -
unused_retaddr:这是用来占位的,没有其他作用。为什么要占位?说来话长。进入 kernel_thread() 时,并不是通过
call指令来调用的,而是ret指令。什么不伦不类、莫名其妙的玩意儿???干嘛用ret来调用函数?读者朋友请别急,笔者初学此处时也是一脸懵逼,现在暂时无法解释,等到下节任务调度时笔者会专门解析这一点,现在只需记住,kernel_thread() 是在switch.s中通过ret指令进入的 。那么问题来了,kernel_thread() 是 C 语言写的函数,C 默认这个函数是 call 调用的,所以在寻参时会跳过 call 指令留下的返回地址(call下一条指令的地址) 。正常调用 kernel_thread() 函数时,其反汇编大致如下:plaintext1
2
3
4
5
6push func_arg
push function
call kernel_thread
;------------------进入kernel_thread后
push [esp-8]
call function其中
[esp-8]就是寻参,寻的是 func_arg 参数,减 8 则是跳过返回地址和 function 参数 。由于我们用的是ret而非call,所以必须手动为 kernel_thread() 营造是 call 指令的假象,即,将原本的返回地址用占位符代替,以确保能够正确寻参。爱思考的读者可能会问,既然我们将返回地址用占位符代替,那这岂不是意味着 kernel_thread() 运行完毕后无法正确地返回?是的,它不能像普通函数那样返回,因为它本身可不普通,它可是运行在线程里的、高贵的函数。哈哈,开个玩笑,这点我们也会在下节中剖析。
-
function 和 func_arg 的作用见上一点。值得一提的是,线程函数(function)的参数必须为 void* !这是为了应对需要向线程函数传递多个参数的情况:当需要传递多个参数时,需要将这些参数包装成结构体,并将结构体指针传入即可。如果不使用此方式,想传几个参数就传几个,那么栈操作就无法统一,任务切换也无从谈起。
-
-
第 53 行的 task_struct 就是我们的线程控制块啦!前三个成员在前文提到过,这里重点讲解 stack_magic 是如何检测 PCB 是否被破坏的。我们已经知道,内核栈在 PCB 的顶部(高地址处),任务信息在 PCB 的底部(低地址处),由于栈是由高地址向低地址扩展的,所以在某些情况下栈可能会覆盖低地址的 task_struct :
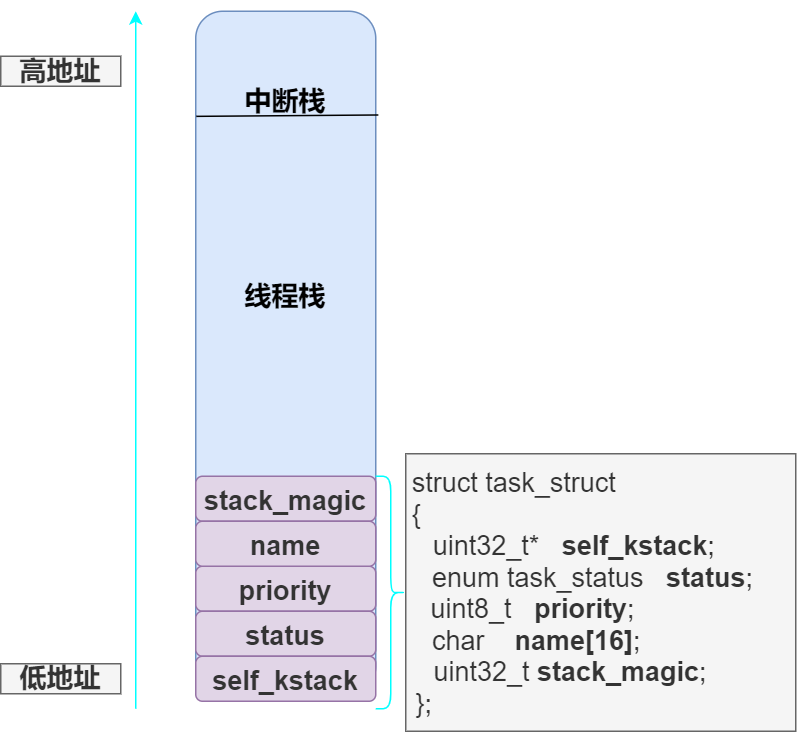
可见,只要 task_struct 被破坏,那么最先被覆盖的一定是 stack_magic(这也是为什么将 stack_magic 声明在最后的原因) ,所以可以通过检测该魔数来判定是否发生破坏。stack_magic 任由你自己决定,应适当复杂。

接着来看 thread.c:
1 | //thread.c |
先理理线程创建的整体思路:
- 调用
thread_start()来创建线程。 - 在
thread_start()中,向内核申请一页物理内存用来存放 PCB 。 - 接着,调用
init_thread()来初始化线程的相关信息,包括任务状态、优先级、内核栈指针、魔数等。 - 然后,调用
thread_create(),将线程函数及其参数写入该线程的内核栈中。 - 最终,切换到线程栈,调用线程函数,任务开始。
代码逻辑比较清晰,下面讲解重点内容:
-
第 40 行,向内核申请一页内存用来存放 PCB 。之前说过,我们的线程采用内核态实现,由内核管理所有线程,所以必须从内核空间申请 。
-
第 12、13 行减去中断栈和线程栈,使 self_stack 指向线程栈的起点,这是为了让线程栈与 self_stack 结构体一一对应,使相关信息能够准确写入线程栈的正确位置。注意,不同于中断栈,我们不会通过 inr_stack 结构体向中断栈赋值或取值;而对于线程栈,我们必须精确赋值,不能将位置搞错,一旦错位,就无法进入线程函数来实行任务啦 !
-
第 18 行,此四个寄存器可初始化为 0,下节你明白为什么。
-
第 44 行就是我们之前常听到的栈切换了,这是任务切换的最关键一步。切换栈很简单,就是通过修改 esp 的指向来完成的。对了,为什么要用静态全局变量 stack 来中转呢?这种用法在assert断言中已经提到过了,由于第 44 行是内联汇编,汇编只认识全局符号 ,所以我们要使用一个全局变量来中转。经过下面的 4 次 pop 后,esp 便指向了 eip,而 eip 在
thread_create()中被指向了kernel_thread()函数,所以接下来的ret指令就会进入到此函数中。之后,kernel_thread()调用function(),开始执行任务。图示如下:

这几句汇编这是我们这节临时使用的方案,下节实现任务切换时会使用正规方法。
-
读者朋友可能已经发现,
thread_create()第三个参数是一个 void 指针,用来传递线程函数所需要的参数。问题是,为什么要用 void 指针来传递参数呢?而且万一要传递多个参数,那怎么办?很简单,将多个参数封装成一个结构体,然后将该结构体的指针传入该函数,然后在线程函数中解包就ok了。那么,传指针是唯一的方法吗?能不能学习 printf,使用可变参数列表来进行传参呢,这样可多方便呐!好问题!当你彻底理解任务调度和切换后(本小节和下一小节),你将明白为什么不能使用可变参数列表。

本文结束,休息一会,请移步线程-进阶-任务调度 。





