实现用户进程—进入用户态
本文前置内容(必看):TSS/LDT/GATE ,中断详解 ,进程的虚拟内存布局、《装载、链接与库》
本节对应代码讲解:实现用户进程-代码详解
概述
操作系统有三大核心功能:内存管理、进程管理、文件管理 。截至目前,我们已经完成了内存管理和进程管理的部分内容,对于内存管理,咋们还差内存回收机制;对于进程管理,由于线程是进程的基础,之前咋们实现了线程,所以进程也就完成了一半;文件管理将在不久后实现文件系统后再进行。
任务切换的原生方式
在 TSS/LDT/GATE 一文中,我们简单了解过 TSS 与 LDT 的作用,明白了 TSS 和 LDT 只是理想中的任务管理和切换的工具: Intel 建议用 TSS 来保存并恢复任务的状态,用 LDT 来保存任务的实体资源 。而考虑到效率问题,现代操作系统并未(完全)使用 TSS 和 LDT 来进行任务切换。至于为什么效率低下,看看其任务切换的具体过程便能体会到:
CPU 原生支持 的任务切换方式有两种:1)中断 + 任务门;2)call / jmp + 任务门;下面分别介绍这两种方式。
中断+任务门
既然是通过中断调用,那么调用方式只能通过中断信号或 int 指令进行,此时任务门也当然是在 IDT 中注册。
调用过程如下:
-
时钟中断发生,处理器自动从该任务门描述符中取出新任务的 TSS 选择子。
之前咋们的时钟中断的向量号对应的是中断门描述符,对应时钟中断处理程序(schedule),而现在我们要使用任务门来切换任务,所以时钟中断向量号就应该指向任务门描述符:
.PNG)
这里笔者有个问题,时钟中断号为 0x20,如果 0x20 指向任务门描述符,那岂不是每次发生时钟中断时,都会切换到同一个任务?那还如何实现任务调度呢?由于我们的操作系统不会使用任务门来进行任务切换(Linux也不会),所以这里就不深究了,直到答案的读者还请麻烦在评论区指点一二。 -
用 TSS 选择子在 GDT 中索引 TSS 描述符。
-
判断该 TSS 描述符的 P 位是否为 1,为 0 则表示对应的 TSS 不在内存中,这将引发异常。
-
从 TR 寄存器中获取旧任务(当前任务)的 TSS 位置,将当前寄存器状态保存到该 TSS 中。
-
将新任务 TSS 中的值加载进相应寄存器。
-
将新任务的 TSS 段选择子加载进 TR 寄存器,这由 CPU 自动完成。
-
将当前任务的 B 位置 1,原因参见TSS/LDT/GATE 。
-
将新任务标志寄存器的 NT 位置 1,原因参见中断详解。
-
将旧任务的 TSS 选择子写入到新任务 TSS 的
上一个任务的TSS指针字段中。 -
开始执行新任务。
返回过程如下:
- 调用
iret,检查 NT 位,如果为 1,则应该返回旧任务而非中断返回。 - 将当前任务的 NT 位置 0 。
- 将当前任务的 TSS 描述符中的 B 位置 0 。
- 将寄存器现场保存到当前 TSS 中。
- 获取当前 TSS 中
上一任务的TSS指针字段,将选择子加载进 TR 。 - 根据 TR 指向的 TSS 恢复寄存器现场。
call、jmp切换任务
任务门除了可以在 IDT 中注册,还能在 GDT 和 LDT 中注册,当在后两者中注册时,就可以通过 call、jmp 指令来切换任务。call 和 jmp 有所不同,前者有去有回,所以通过 call 调用的新任务可以认为是旧任务的分支,本质上它们算是同一个任务 ;而 jmp 则是有去无回,新旧任务之间没有关系。此二者的区别体现在是否将旧任务的 B 位置 0 ,先以指令 call 0x0018:0x1234 来看 call 的任务调用过程:
0x0018表示在 GDT 中索引第 3 号描述符,即任务门描述符。不同于普通段描述符,任务门描述符中记录的是 TSS 选择子,所以处理器自动忽略0x1234。- 检查 P 位,为 0 则表示该描述符不在内存中,抛出异常。
- 检测 S 和 TYPE 位,判断描述符类型,如果是任务门描述符,则检查 B 位,若为 1 则抛出异常。
- 特权级检查,数值上 CPL 和 TSS 选择子中的 RPL 都要小于或等于 TSS 描述符的 DPL,关于特权级检查与 RPL、CPL、DPL 的区别,详见特权级剖析 。
- 将当前任务的现场保存到 TR 寄存器所指向的 TSS 中。
- 将新任务的 TSS 选择子加载到 TR 寄存器中。
- 将新任务 TSS 中的寄存器载入到相应寄存器中,并进行特权级检查。
- 将新任务的 NT 位置 1,表示为任务嵌套,以便 iret 时从新任务返回到旧任务,而非从中断返回。
- 将旧任务的 TSS 选择子写入到新任务 TSS 中
上一任务的TSS指针字段中,以便能够返回。 - 将新任务的 B 位置 1 以表示当前任务忙,但旧任务的 B 位仍然为 1,不会置零 ;
- 切换完成,新任务开始。
任务返回则同上文中断调用相同。
jmp 的任务调度过程和 call 几乎相同,只是第 10 步 B 位置零有所不同:由于 jmp 有去无回,所以新旧任务不构成链式关系,因此会将旧任务的 B 位置 0 。
从以上过程便能看出,CPU 原生的任务调度方式很是繁杂,这降低了任务切换的效率和灵活性,因此现代操作系统都没有采用这种方式。
任务切换的现代方式
虽然咋们没有用 Intel 建议的方式来进行任务调度,但这也不是说 TSS 就一无是处了(LDT 是真的完全成孤儿了),Linux 在以下两个地方还是会用到 TSS:
-
I/O 特权级控制
我们一直认为用户进程无法直接访问硬件,必须通过操作系统才行;但是,为了在某些场景下快速反应,TSS 中的 I/O 位图为用户程序直接控制硬件提供了途径。提示:我们的操作系统并不会使用 IO 位图。
-
将进程的内核栈记录在 TSS 中的 SS0 和 ESP0 位置处
我们通过时钟中断来进行任务调度,在中断详解一文中提到,当发生中断并引用中断门描述符时,会检查是否发生特权级转移,如果特权级改变,则会自动转移到新栈,这个新栈就从 TSS 中获取 。换句话说,一个任务分为用户部分和内核部分,从用户转移到内核时,CPU 就会 自动 切换到内核自己的栈。
同时注意,Linux 只使用一个 TSS ,任务切换时并不会随之切换 TSS,而是只修改 TSS 中的 ESP0 ,这样也会大大提高任务切换的效率。后文解析代码时,读者朋友就能清楚地看到这一过程。
进程的实现方式
Windows 对线程和进程的实现如同教科书一般标准,不仅在概念上对线程和进程有明确的区分,在 API 上也是如此:使用 CreateProgress 和 CreateThread 来分别创建进程和线程。而在 Linux 下就不存在明显的线程概念,其将所有的执行实体都称为任务(task),并由 task_struct 结构体负责管理任务(这点对于理解进程和线程的关系至关重要),这在线程基础中有代码说明 。每个任务都类似于单线程,具有内存空间、执行实体(寄存器)、文件资源等,但不同的任务可以选择共享同一虚拟内存空间,因此,共享了同一个内存空间的任务集合构成了一个进程 。
我们的操作系统是仿 Linux 系统,所以咋们实现用户进程就能够以线程为基础,具体方式如下:
先回顾线程创建的大概流程:
- 调用
thread_start()来创建线程。 - 在
thread_start()中,调用 get_kernel_page() 向内核申请一页物理内存用来存放 PCB 。 - 接着,调用
init_thread()来初始化线程的相关信息(task_struct),包括任务状态、优先级、内核栈指针、魔数等。 - 然后,调用
thread_create(),将线程函数及其参数写入该线程的内核栈中。 - 最终,切换到线程栈,调用线程函数,任务开始。
要以线程为基础实现进程,就只需要将执行普通任务的线程函数替换成创建进程的新函数(即start_progress)即可 。那么,具体创建进程的流程是怎么样的呢?见下图:
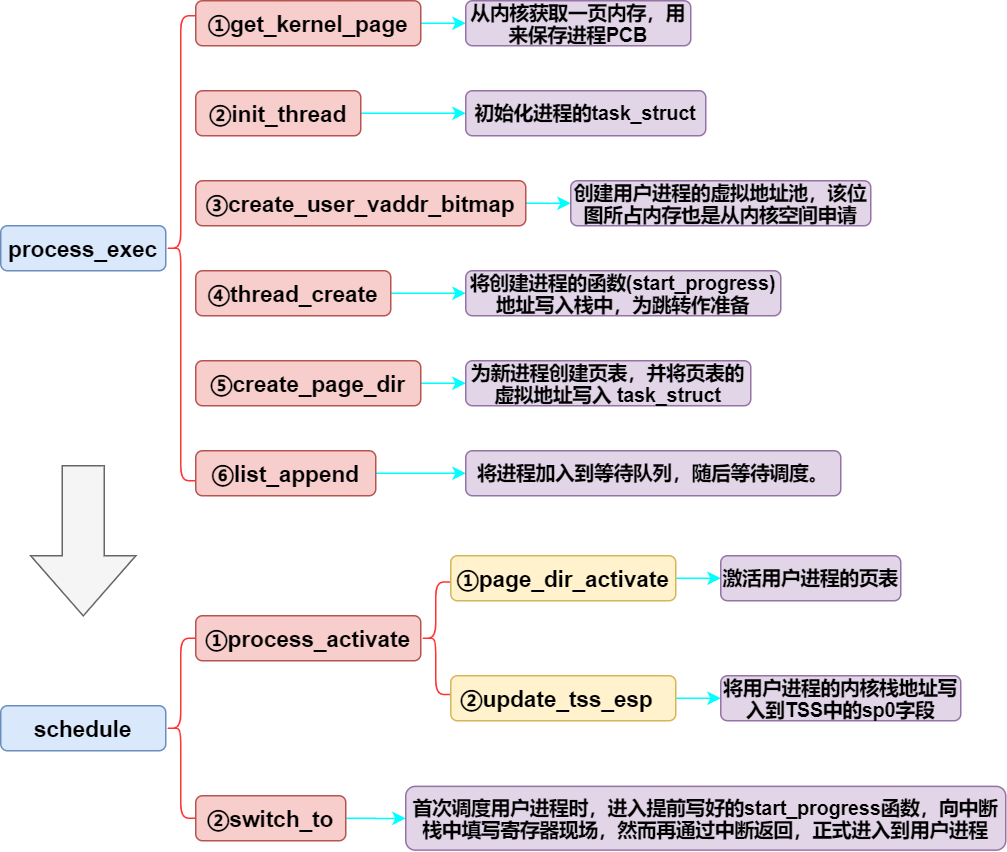
以上函数具体的实现待会再说,先来看看程序是如何进入到用户进程的。我们已经知道如下几点:
- 用户进程运行在 3 特权级(ring3),而内核则运行在 ring0;
- 在特权级剖析一文中我们了解到,除了返回指令(retf, iret/iretd),任何时候都不允许将控制从高特权级转移到低特权级上。

- 一直以来我们都在内核中运行,即执行流一直停留在 ring0 。
那么现在,要在内核中,即 ring0 下创建用户进程,并进入到 ring3 用户态,该怎么做呢?显然,只能通过中断返回,即 iret 进入用户态。所以我们采用的具体办法是:利用之前的方式创建线程,将线程里运行的函数设置为 start_progress() ;然后在 start_progress 中初始化该线程的中断栈(也就是将用户进程的寄存器现场提前写入中断栈);最后 iret 中断返回,即可 ring0 -> ring3,进入用户态。
其实这种方式可以说是瞒天过海,妥妥地欺骗了 CPU。我们用 iret 指令使 CPU 以为咋们处于中断处理环境中,于是便假装从中断返回,顺利通过特权级检查并进入用户态。
用户进程的虚拟内存分布
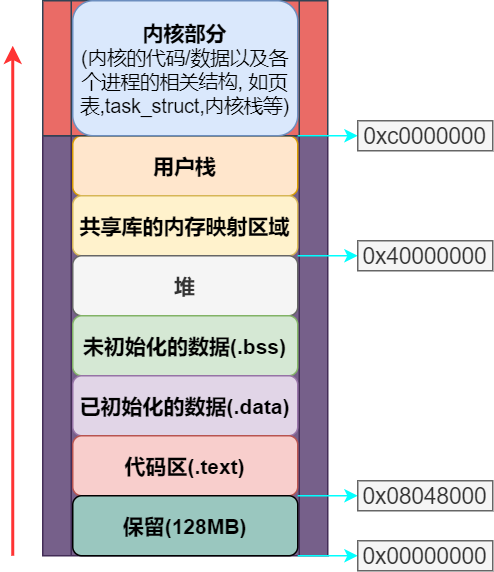
上图是经典的 Linux 用户进程内存布局(内核2.4版本) ,下面依次对各个部分作简单阐述:
-
3GB~4GB 虚拟内存映射为内核空间,由所有进程共享。
-
用户内存的顶部是用户栈。一般而言,用户栈的最大空间为 8MB,详见Linux进程栈空间大小 - Tiehichi’s Blog。另外,用户栈的最高处会用来保存命令行参数和环境变量,这些数据是由 C 运行库压入的,后续从文件系统加载进程时会再提及此处。
-
用户栈下面是共享库的内存映射区域。共享库就是动态链接库,一个共享对象(即.so文件)由所有用户进程共享。举个例子,A 进程用到了 math 库,B进程也用到了 math 库,则 math 库会被加载到物理内存中,进而被映射到各个进程的虚拟内存空间中,由此实现共享,大大节省了内存,这便是动态链接库相对于静态链接库的优势。
-
接着是运行时堆,用于满足程序运行时的动态内存需求。
-
.bss 用于保存未初始化的数据,如未初始化的静态变量和全局变量。
-
.data 段用来保存已初始化且可读写的数据。实际上还有 .rodata 用来存放只读数据,此段并未体现在图中。
-
.text 则是代码区。IA-32 体系结构中,进程空间的代码段都从
0x08048000开始,这与最低可用地址0x00000000有 128M 的间距。关于
0x08048000这个值有许多解释,Linker And Loader一书给出的解释如下:
在 386 系统上,代码的起始虚拟地址是0x08048000,这允许在代码下方有一个相当大的堆栈;同时保持在地址0x08000000上方,允许大多数程序使用单个二级页表(回想一下,在 386 上,每个页目录项映射 0x00400000 大小的空间)。其他原因可参见0x08048000由来
关于进程的虚拟内存分布,这将在《 链接、装载与库 》系列笔记中详细阐述,敬请期待。




